Why Choose LLUMO AI?
Key Features
- Data Upload Made Easy: Test with your data directly, ensuring tailored results.
- Advanced Evaluation Tools: Use cutting-edge techniques like RAGAs and LLUMO Eval LM for one-click evaluations.
- Customizable KPIs: Tailor over 50 metrics to measure what matters most to your project.
- Actionable Insights: Real-time data to refine your models for speed, accuracy, and cost-efficiency.
- Multi-Industry Applications: From legal research to customer service, LLUMO AI adapts to any domain.
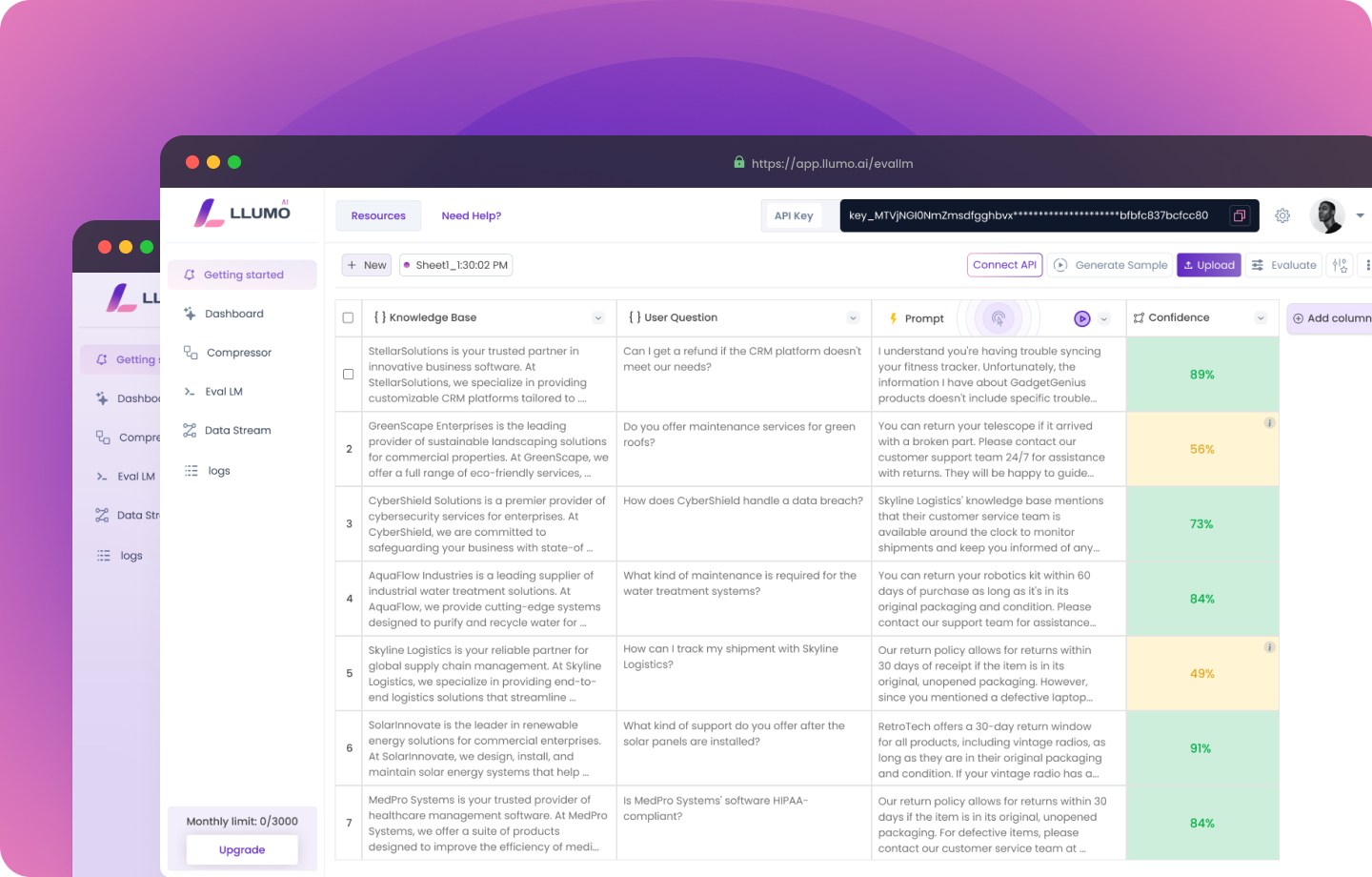
Getting Started with LLUMO AI
Step 1: Create an Account
- Action: Sign up for a LLUMO AI account [here].
- Why: Gain access to the full range of features for testing, optimizing, and improving your AI models.
Step 2: Upload Your Data
- Action: Upload data in formats like CSV, JSON, or plain text.
- Why: Tailor results specific to your needs by securely uploading your data.
Step 3: Experiment with Prompts
- Action: Use the Playground to create and test prompts for your project.
- Why: Crafting the right prompts ensures accurate and relevant AI responses.
Step 4: Evaluate Performance
- Action: Compare prompts and results using tools like RAGAs and LLUMO Eval LM.
- Why: Quickly identify what works best for smarter decision-making.
Step 5: Customize KPIs
- Action: Set metrics like accuracy, speed, or relevance to align with your goals.
- Why: Tailored KPIs give you more control over your project’s success.
Step 6: Iterate and Optimize
- Action: Refine prompts and workflows using insights from LLUMO AI.
- Why: Continuous improvements lead to better results and a smoother workflow.
Step 7: API Integration
- Action: Use the Connect API section to integrate LLUMO AI with your models.
- Why: Automate tasks and streamline workflows efficiently.
Tools and Techniques
LLUMO AI Playground
- Problem: Testing and improving AI models can be time-consuming.
- Solution: A one-stop shop to upload data, test prompts, and evaluate performance.
Customizable Evaluation Metrics
- Problem: Standard metrics may not suit your needs.
- Solution: Tailor KPIs to measure what matters for your project.
Advanced Evaluation Tools
- Problem: Evaluating AI performance without the right tools is difficult.
- Solution: Tools like RAGAs and LLUMO Eval LM provide clear insights for improvements.
Prompt Compression
- Problem: Running LLMs with lengthy prompts is expensive.
- Solution: Compress prompts to save costs while maintaining performance.
Real-Time Insights
- Problem: Tracking AI performance in real-time can be challenging.
- Solution: View and refine performance instantly with LLUMO AI’s real-time insights.