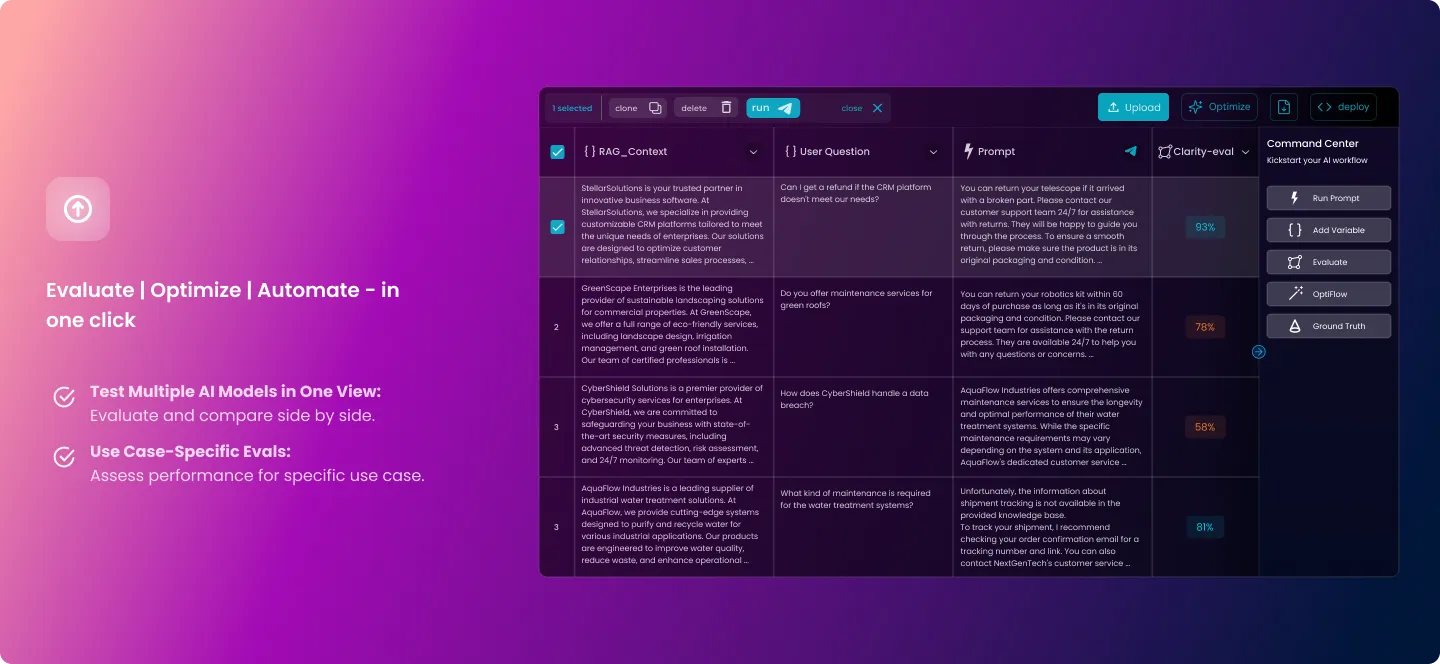
Why You Need LLUMO AI Experiment
If your AI development process faces challenges like:- Unreliable Model Performance: Struggling to measure accuracy, relevance, or hallucination rates effectively.
- Slow Experimentation: Testing models manually, leading to bottlenecks in iteration and deployment.
- Lack of Use Case-Specific Evaluations: Generic benchmarks that don’t reflect your business needs.
- High Debugging Effort: No structured way to trace and fix model failures at scale.
Core Features of LLUMO AI Experiment
- Test Multiple AI Models in One View: Evaluate a range of AI models and compare them side by side, all from a single interface.
- Use Case-Specific Evals: Assess the performance of your AI workflows using evaluations tailored to your specific use case.
- Cutting-Edge KPIs for Conversational AI: Measure outputs against various KPIs like RAGAs, hallucinations, and other in-house metrics.
- One-Click Deployment: Deploy with ease using a simple one-click setup that works with your software or platform, and integrate seamlessly with other tools.
Quick Start - Related Documentation
The Quick Start section is designed to help you get up and running with LLUMO AI’s evaluation tools in the fastest and most efficient way. Whether you’re setting up for the first time or integrating evaluations into production, these guides provide step-by-step instructions tailored to different use cases. LLUMO AI’s Experiment Playground allows you to tailor the evaluation process to meet your unique requirements. Whether you’re analyzing customer service data, academic content, or any other dataset, this powerful tool enables users to assess AI-generated outputs against tailored metrics and criteria that align with their specific needs and objectives. Unlike pre-defined evaluation methods, which may not fully capture the nuances of different use cases, LLUMO AI’s evaluation allows users to define their own parameters, ensuring the evaluation process is both relevant and effective. This guide will walk you through the steps of using Experiment playground to perform a detailed and personalized evaluation of your datasets.Step-by-Step Instructions: Evaluating using Custom Evaluation
Step 1: Upload Your Dataset
Option 1: Upload File- Log into LLUMO AI Platform and navigate to the “Eval LM” section.
- Upload Your Dataset: Click “Upload File” and select your dataset. Supported file formats include CSV, JSON, and Excel.
- Review Your Data: A preview of the uploaded data will appear. Check that the structure and content are correct before moving forward.
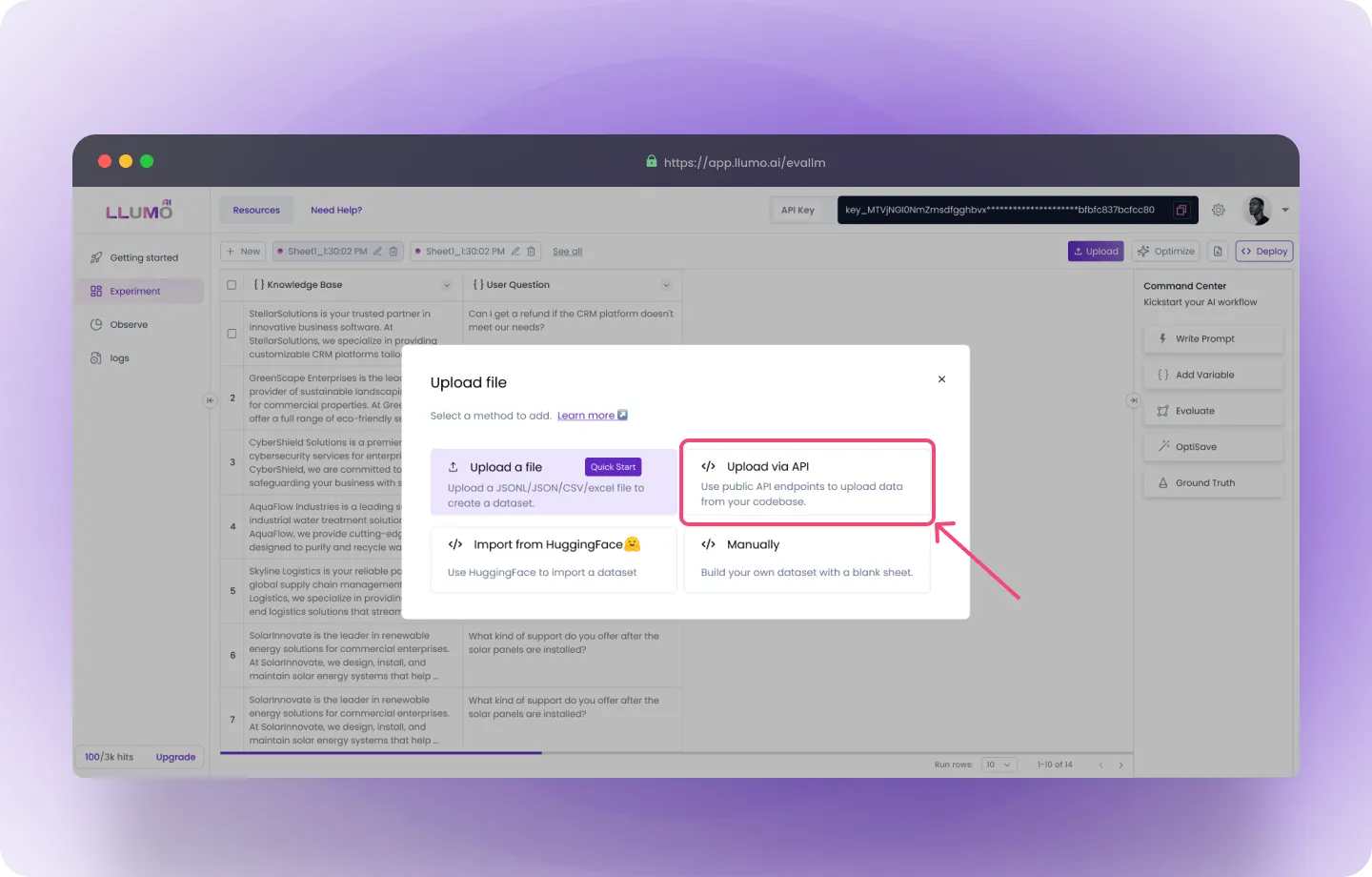
- Enter URL: You can enter either a private or public URL that returns data in JSON format.
- Enter Headers: In the request, include any necessary headers. Typically, headers are used to pass authentication keys (like API keys) or specify content types.
- Enter JSON Payload: The JSON payload is where you attach the data to be sent, including any filters or data for processing. This can be used to send files, parameters, or other information.
- Enter JSON Path: After the request is processed, you may need to extract specific data from the API response. Use a JSON path to locate and retrieve the relevant part of the response.
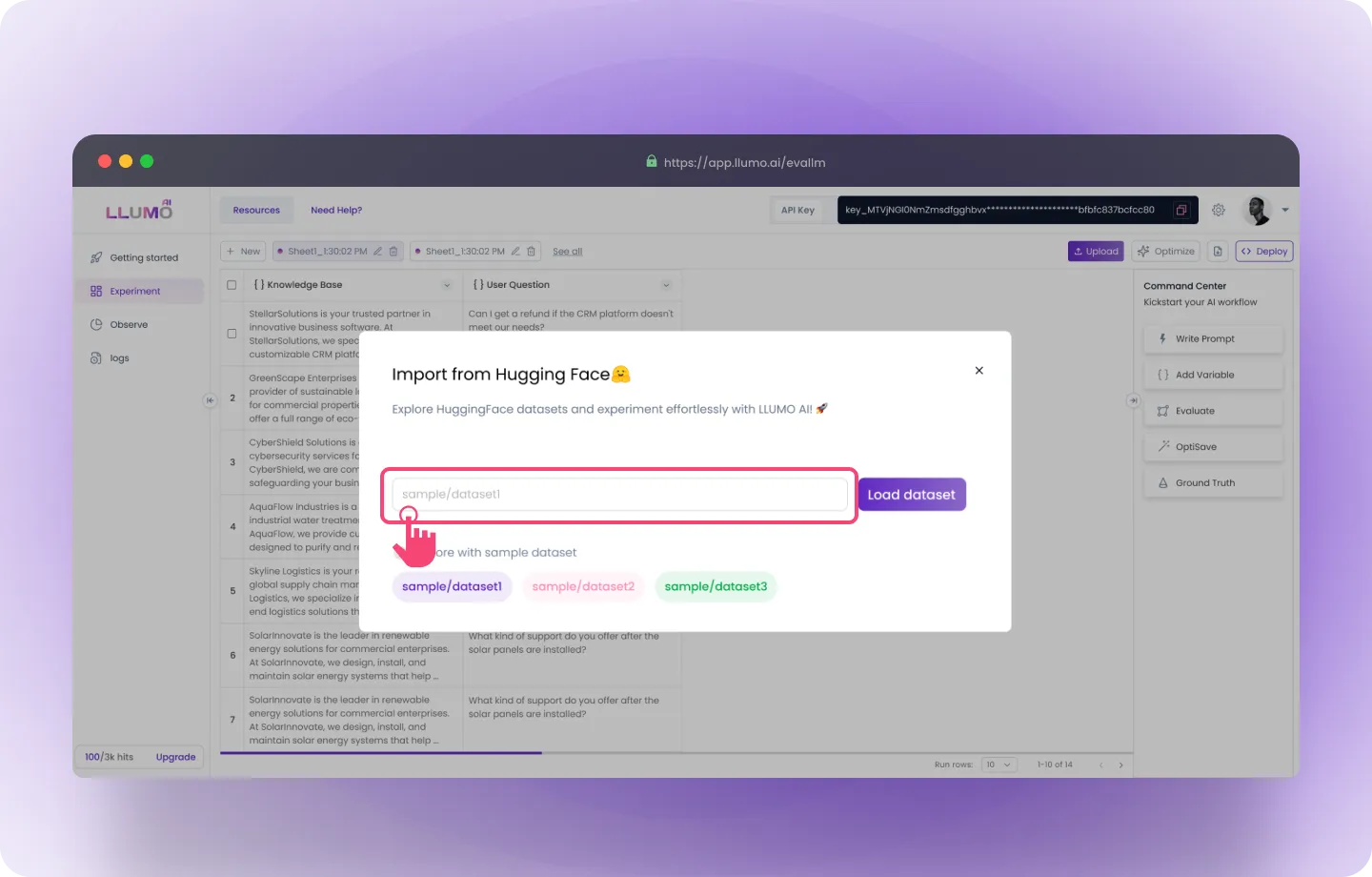
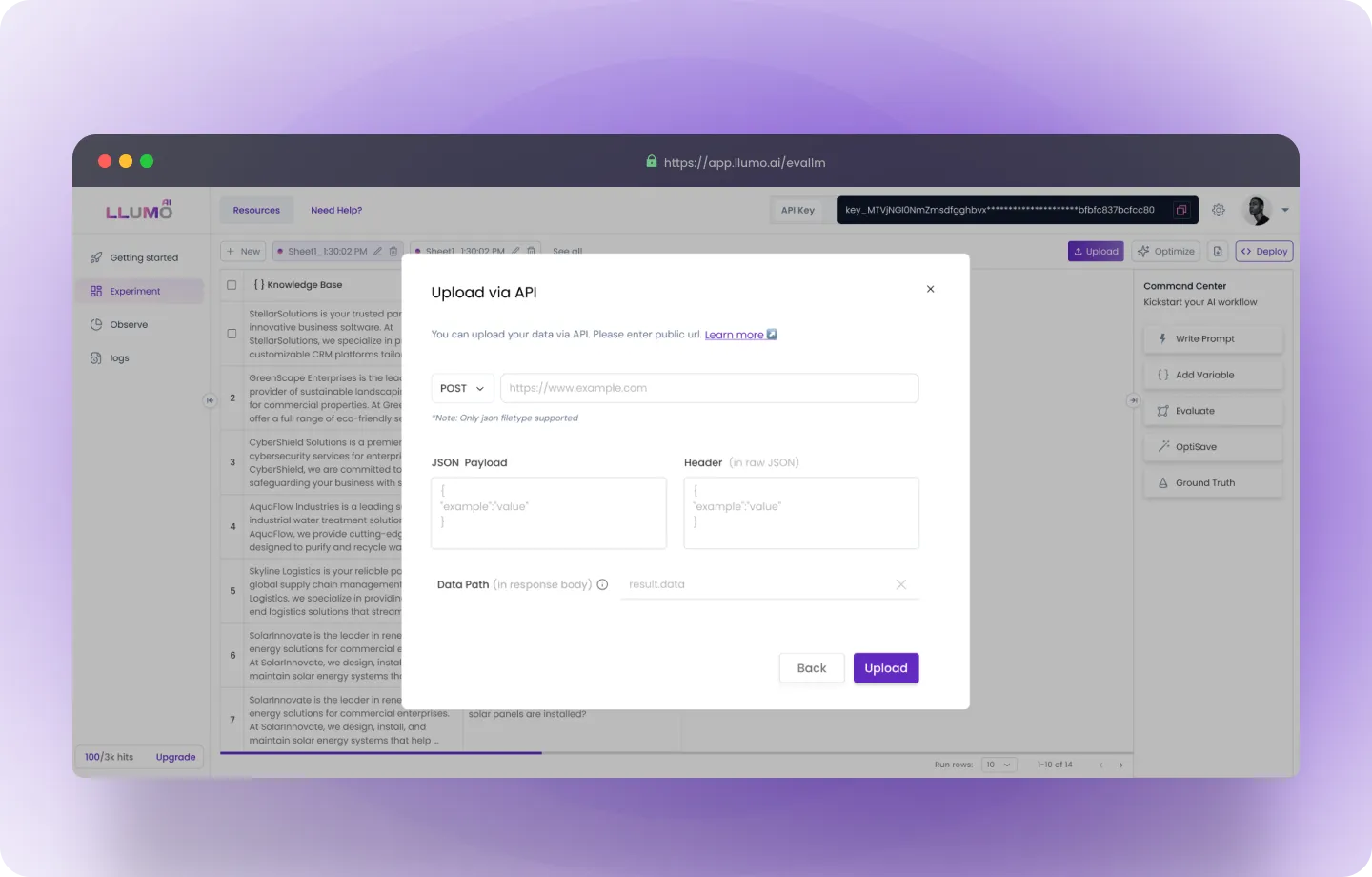 Option 3: Import from Hugging Face
Option 3: Import from Hugging Face
- Open Hugging Face: Go to Huggingface Datasets
- Copy the Dataset Name: Find the dataset you want to use and copy its name.
- Open LLUMO: Go to Experiments page on LLUMO AI
- Upload Dataset: Click on Upload and select Import from Hugging Face
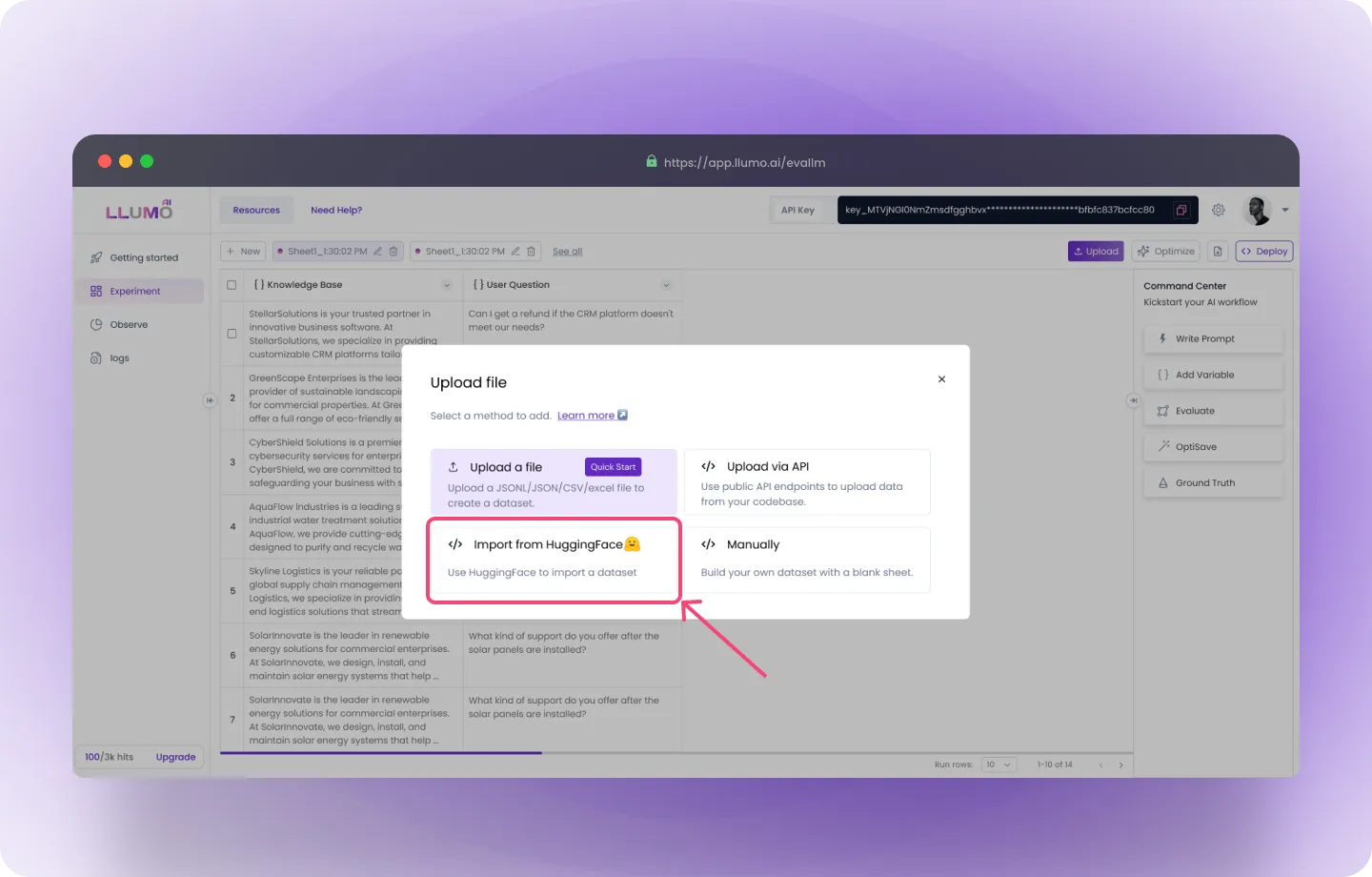
- Paste the Dataset Name: Paste the name of the dataset you copied from Hugging Face
- Select Subset and Tree: Choose the appropriate subset and tree for your dataset
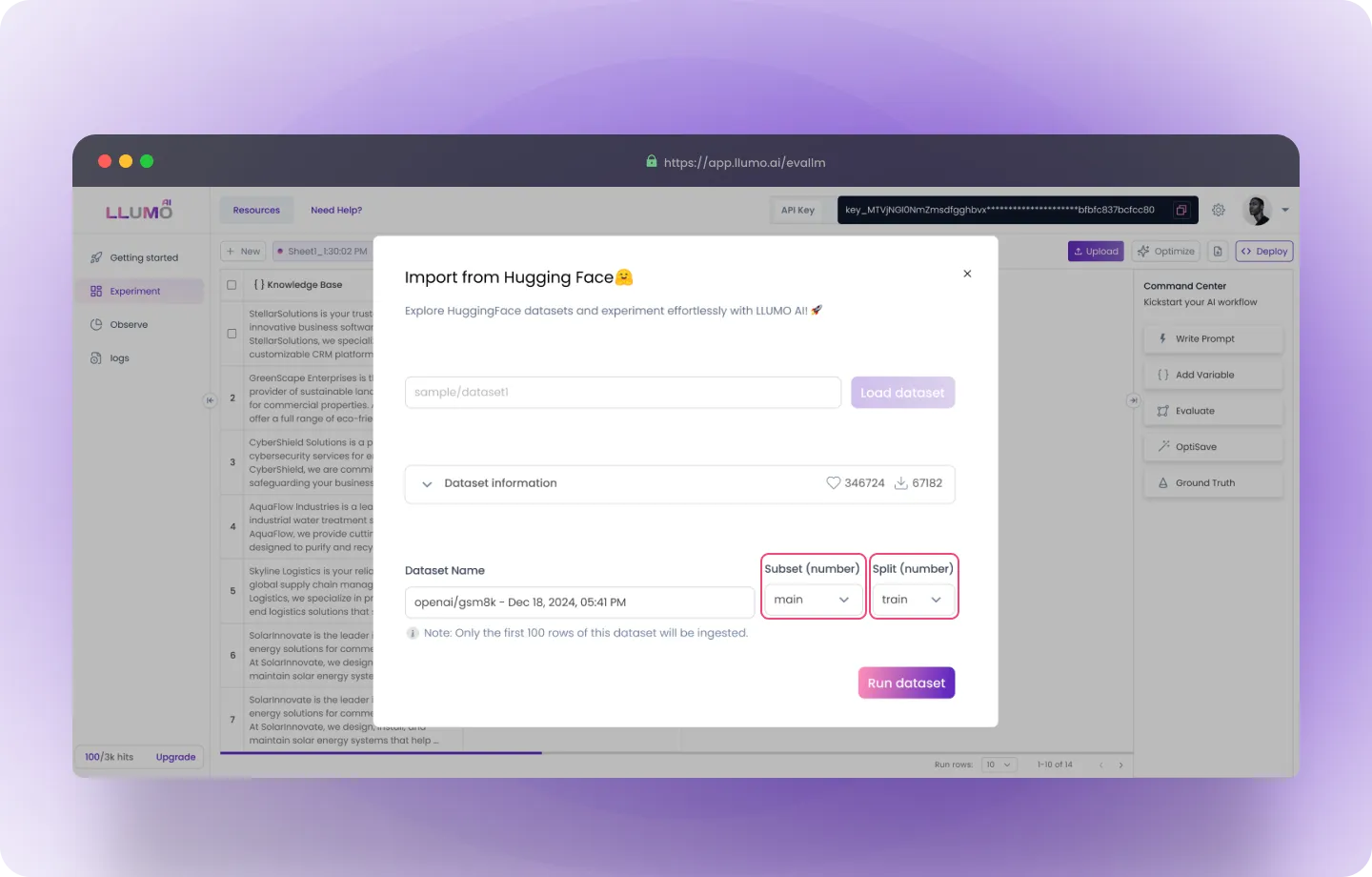
- Import the Data: Click Run Dataset to bring the dataset into LLUMO
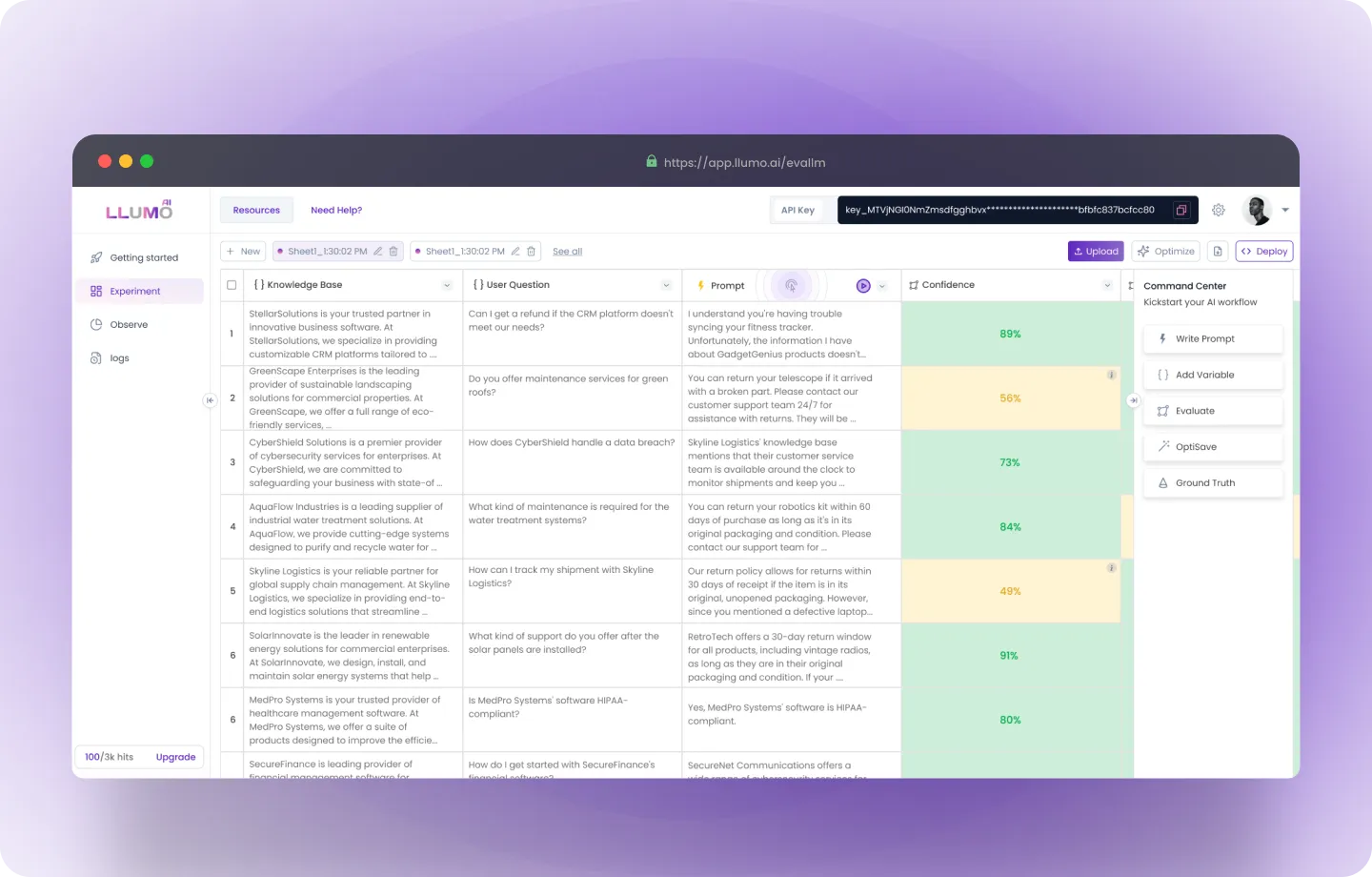
- Perform Evaluation: Once the dataset is imported, you can start the evaluation process.
A dataset is a collection of data used for training or evaluation.
A subset refers to a specific portion of the dataset.
A tree may refer to a hierarchical structure within the dataset or model. Option 4: Manually
Here, you can create a custom dataset by starting with a blank dataset.
Step 2: Click on the Write Prompt card in the command centre.
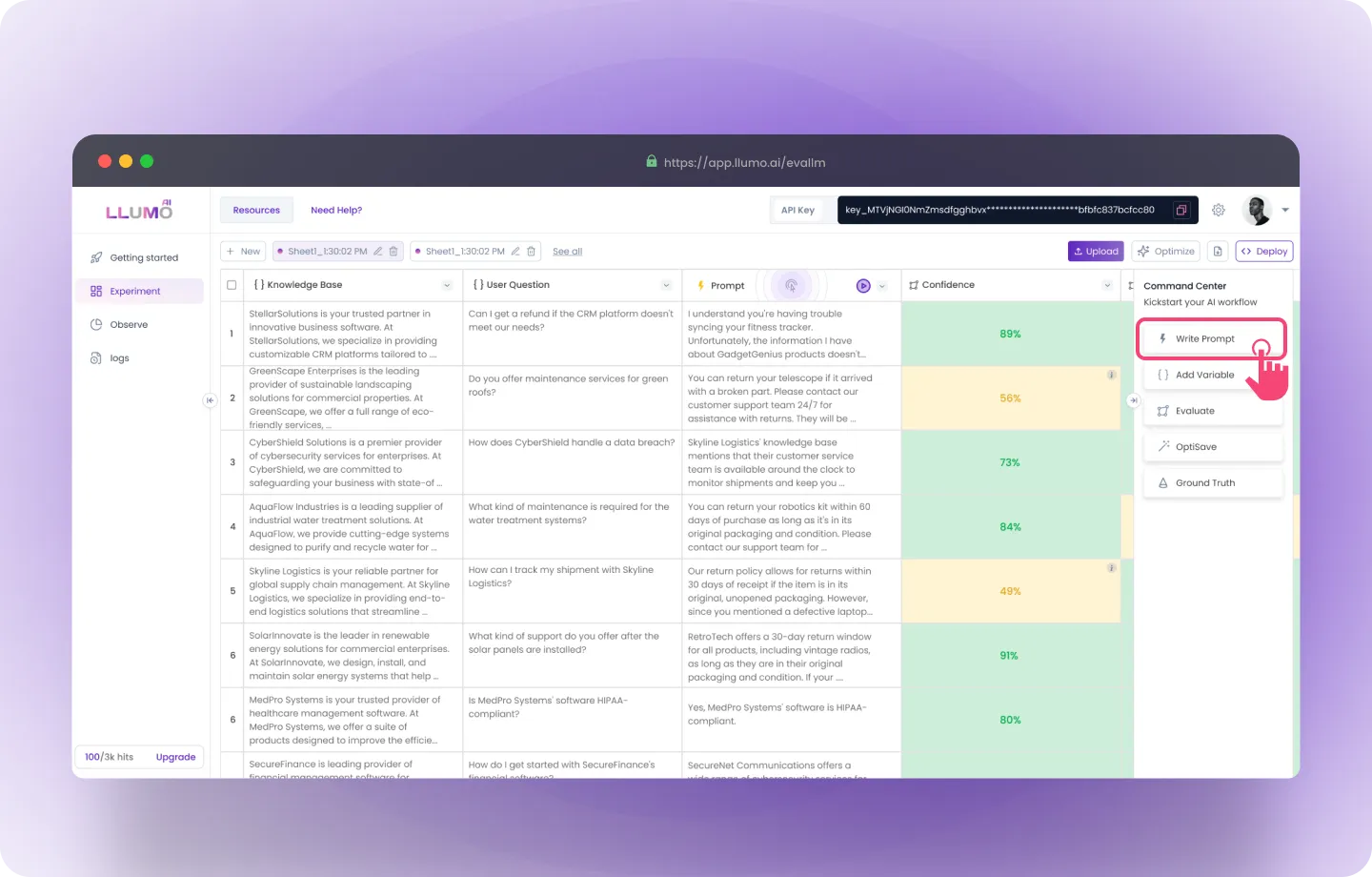 Here, you can follow these steps:
Here, you can follow these steps:
- Column Name: Enter the column name.
- Write Prompt: Enter your prompt by providing the desired query or instruction to guide the AI model in generating the results you expect.
- Create a Smart Prompt (optional): Smart Prompt refines your written prompt, making it more specific and detailed to generate more accurate and focused results.
- Select Your LLM Provider: Choose your preferred provider from the drop-down list (LLUMO supports multiple LLM providers).
- Choose the Model: Select the specific AI model you want to use for generating the results, based on your needs.
- Adjust Parameters: Fine-tune the model’s parameters as per your requirements.
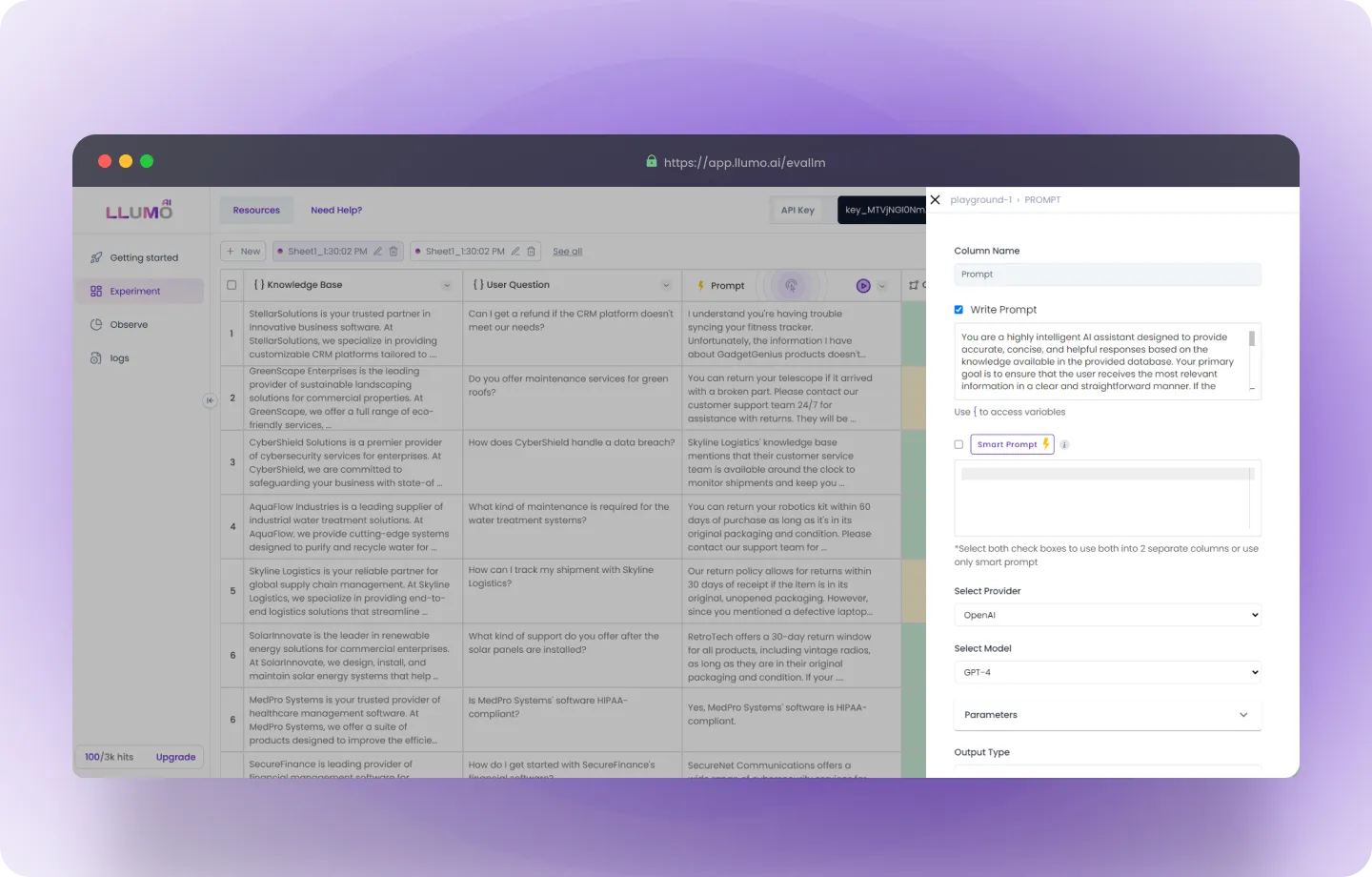
Step 3: Click on the “Create and Run all Columns” button.
- Allow the system to complete processing your prompts.
- Once the outputs are ready, proceed to the evaluation step.
Step 4: Evaluation
- Click on the “Evaluate” card in the command center.
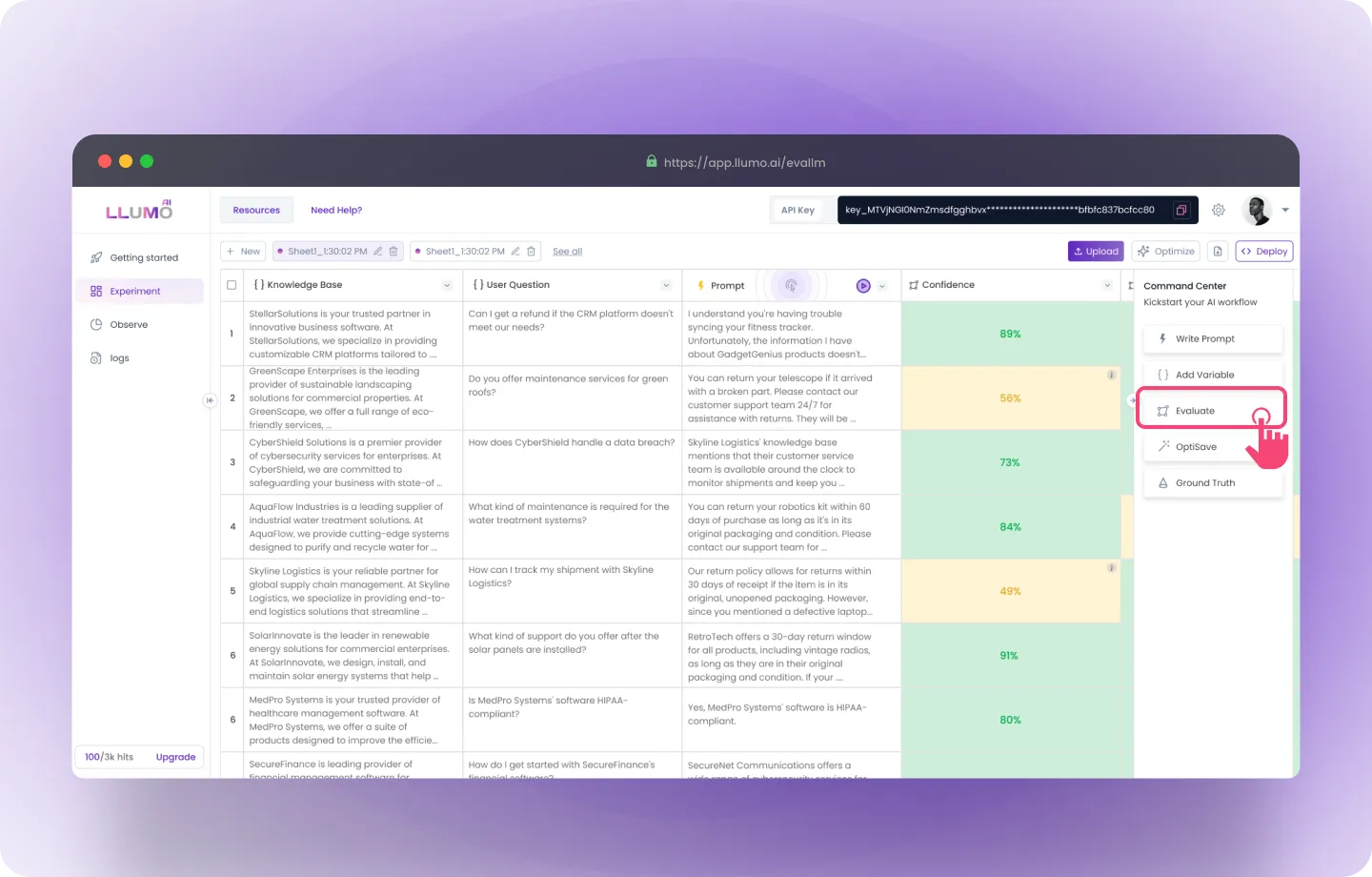
- Now, enter the column name and select the “KPI” as per your use case.
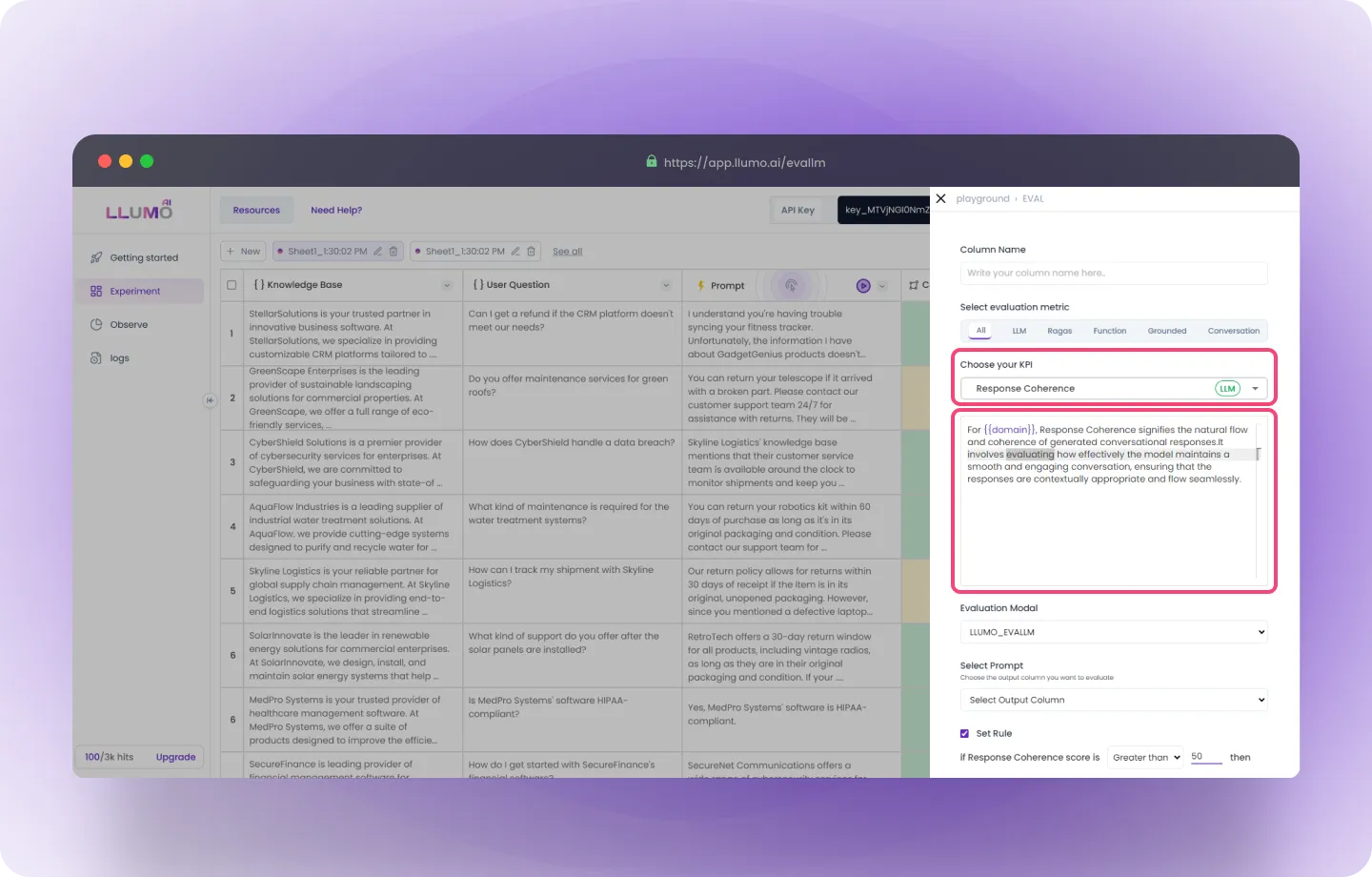 Note: You can customize your evaluations to align with your unique use case and industry requirements.
Note: You can customize your evaluations to align with your unique use case and industry requirements.
- Select your Evaluation model from the drop-down list.
- Select the prompt you want to evaluate.
- “Pass & Fail” criteria
Example for confidence: If the confidence score is more than 50, it passes.
Step 5: Run the Evaluation
- Start the Evaluation: After confirming your settings, click the “Create and Run All Columns” button to begin processing your evaluation.
- Review Evaluation Results: The evaluation will return detailed results, including Pass/Fail status for each KPI along with the scores.
Tailor evaluation metrics and configurations to suit your specific use case
Customize Evaluation
Setup Prompt Evaluation API
Create Custom Evaluation
Evaluate a Bulk Dataset Using 3–4 Metrics
Run Evaluation in Production
Optisave
This Quick Start guide ensures you can navigate LLUMO AI’s evaluation framework effortlessly, saving time and enhancing the quality of your LLM deployments.
API Integration
Integrating LLUMO AI’s evaluation API into your codebase allows for seamless automation of LLM performance tracking, enabling large-scale and efficient evaluations. Follow these steps to get started:-
Set Up API Access
- Obtain your API key from the LLUMO AI dashboard.
- Install required dependencies for API communication.
- Configure authentication for secure API access.
- Read the Full API Setup Guide
-
Evaluate LLMs Using API
- For OpenAI models: Run evaluations on OpenAI’s GPT-based models using LLUMO AI’s API.
- Evaluate OpenAI Models
- For Vertex AI models: Perform evaluations on Google Cloud’s Vertex AI models.
- Evaluate Vertex AI Models
- For OpenAI models: Run evaluations on OpenAI’s GPT-based models using LLUMO AI’s API.
-
Make Your First API Call
- Authenticate your request using your API key.
- Send evaluation requests with input prompts and expected responses.
- Define custom evaluation metrics to measure LLM output quality.
- Integrate API into Your Codebase
-
Create Evaluation Analytics API
- Generate detailed analytics for LLM evaluation runs.
- Monitor performance trends and optimize responses over time.
- Create Eval Analytics API
FAQ
Q. What is LLUMO AI Experiment?LLUMO AI Experiment is a powerful platform designed to help teams test, evaluate, and optimize their LLM applications efficiently. It provides end-to-end tracking, customizable evaluation metrics, and structured experimentation workflows. Q. How does LLUMO AI Experiment help improve LLM performance?
It allows users to:
- Run structured experiments to compare model outputs.
- Identify failure points with detailed tracing.
- Leverage automated and custom evaluation metrics.
- Optimize configurations based on real-time insights.
LLUMO AI offers:
- Prebuilt Metrics: Guardrail metrics for accuracy, coherence, relevance, and hallucination detection.
- Custom Metrics: Define your own KPIs based on your specific use case.
- Obtain an API key and configure authentication.
- Send evaluation requests with input prompts and expected outputs.
- Automate and scale evaluations using scheduled API calls.
Read the Full API Integration Guide
Yes! LLUMO AI allows you to evaluate large datasets using multiple key metrics to assess LLM performance at scale.
Guide to Bulk Evaluation Q. Does LLUMO AI support OpenAI and Vertex AI models?
Yes, LLUMO AI supports evaluation for:
- OpenAI models – Evaluate OpenAI Models
- Vertex AI models – Evaluate Vertex AI Models
LLUMO AI Experiment includes an Experiment Management feature that logs all test runs, allowing you to compare different configurations and monitor long-term performance. Q. How do I create analytics for my evaluation runs?
LLUMO AI provides an Evaluation Analytics API that generates performance insights and trends.
Create Eval Analytics API