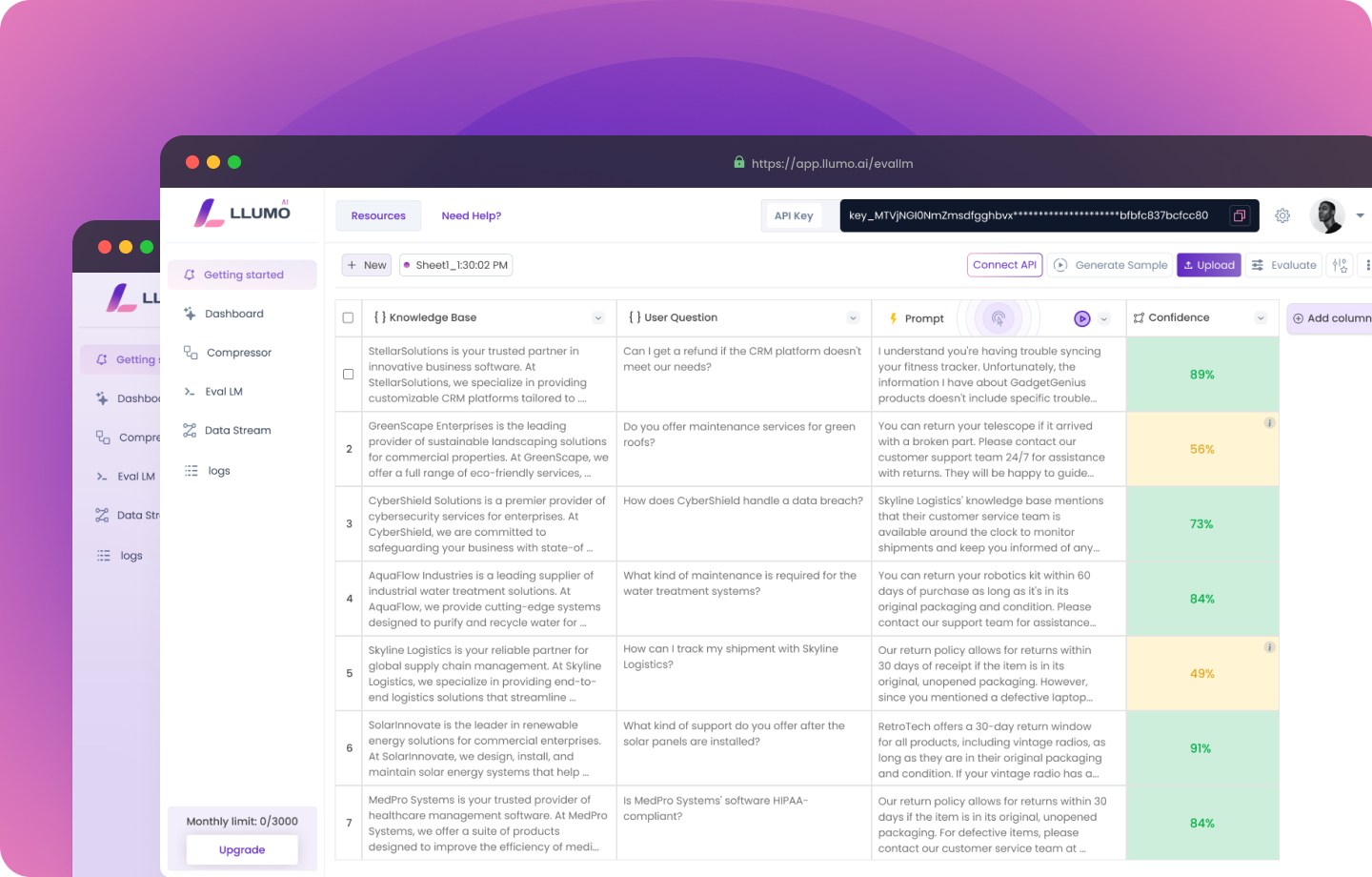
Setting up the environment
Importing libraries:
- os: This module provides a way to use operating system dependent functionality, like reading environment variables.
- OpenAI: This is the official OpenAI Python client, used to interact with OpenAI’s API.
- requests: A popular library for making HTTP requests in Python.
- json: Used for parsing JSON data, which is common in API responses.
- logging: Provides a flexible framework for generating log messages in Python.
- getpass: Allows secure password prompts where the input is not displayed on the screen.
Setting up logging:
- We use
logging.basicConfig()to configure the logging system. Thelevel=logging.INFOargument sets the threshold for logging messages to INFO level and above. - We create a logger object named logger that we’ll use throughout our script to log important information and errors.
Secure API key handling
Secure API key input:
- We use
getpass()to prompt the user for their API keys. This function hides the input, making it more secure than using regular input(). - This approach is safer than hardcoding API keys in your script, which could accidentally be shared or exposed.
Setting environment variables:
- We use
os.environto set environment variables for both API keys. - Environment variables are a secure way to store sensitive information, as they’re not part of your code and are only accessible within the current process.
Initializing the OpenAI client:
- We create an instance of the OpenAI client using the API key we just set.
- Using
os.getenv("OPENAI_API_KEY")retrieves the API key from the environment variables.
Define Llumo compression function
Function definition:
- We define a function
compress_with_llumothat takes a text input and an optional topic.
API setup:
- We retrieve the Llumo API key from environment variables.
- We set the API endpoint and prepare headers for the HTTP request.
Payload preparation:
- We create a payload dictionary with the input text.
- If a topic is provided, we add it to the payload.
API request:
- We use
requests.post()to send a POST request to the Llumo API.response.raise_for_status()will raise an exception for HTTP errors.
Response parsing:
- We parse the JSON response and extract the compressed text and token counts.
- We calculate the compression percentage.
Error handling:
- We use a try-except block to catch potential errors:
- JSON decoding errors
- Request exceptions
- Unexpected response structure
- If an error occurs, we log it and return the original text with failure indicators.
Return values:
- The function returns a tuple containing:
- Compressed text (or original if compression failed)
- Success boolean
- Compression percentage
- Initial token count
- Final token count
Define example prompt and test without compression
Defining the prompt:
- We create a detailed prompt about photosynthesis. This serves as our example text for compression.
Testing without compression:
- We use the OpenAI client to send a request to the GPT-3.5-turbo model.
- The messages parameter follows the chat format:
- A system message sets the AI’s role.
- A user message contains our prompt.
Displaying results:
- We print the AI’s response to the prompt.
- We also print the total number of tokens used, which is important for understanding API usage and costs.
Test with Llumo compression
Applying Llumo compression:
- We call compress_with_llumo() with our example prompt.
- The function returns multiple values, which we unpack into separate variables.
Checking compression success:
- We use an if statement to check if compression was successful.
- If successful, we print compression statistics: percentage, initial and final token counts.
Using the compressed prompt:
- If compression succeeded, we use the compressed prompt in our API call to GPT-3.5-turbo.
- We use the same message structure as before, but with the compressed prompt.
Displaying results:
- We print the AI’s response to the compressed prompt.
- We print the number of tokens used with the compressed prompt.
Handling compression failure:
- If compression fails, we print a message indicating this.
- In a real application, you might want to fall back to using the original prompt in this case.