Step-by-Step Instructions: Evaluating a Bulk Dataset of chatbot using 3-4 Evaluation metrics
Step 1: Upload Your Dataset
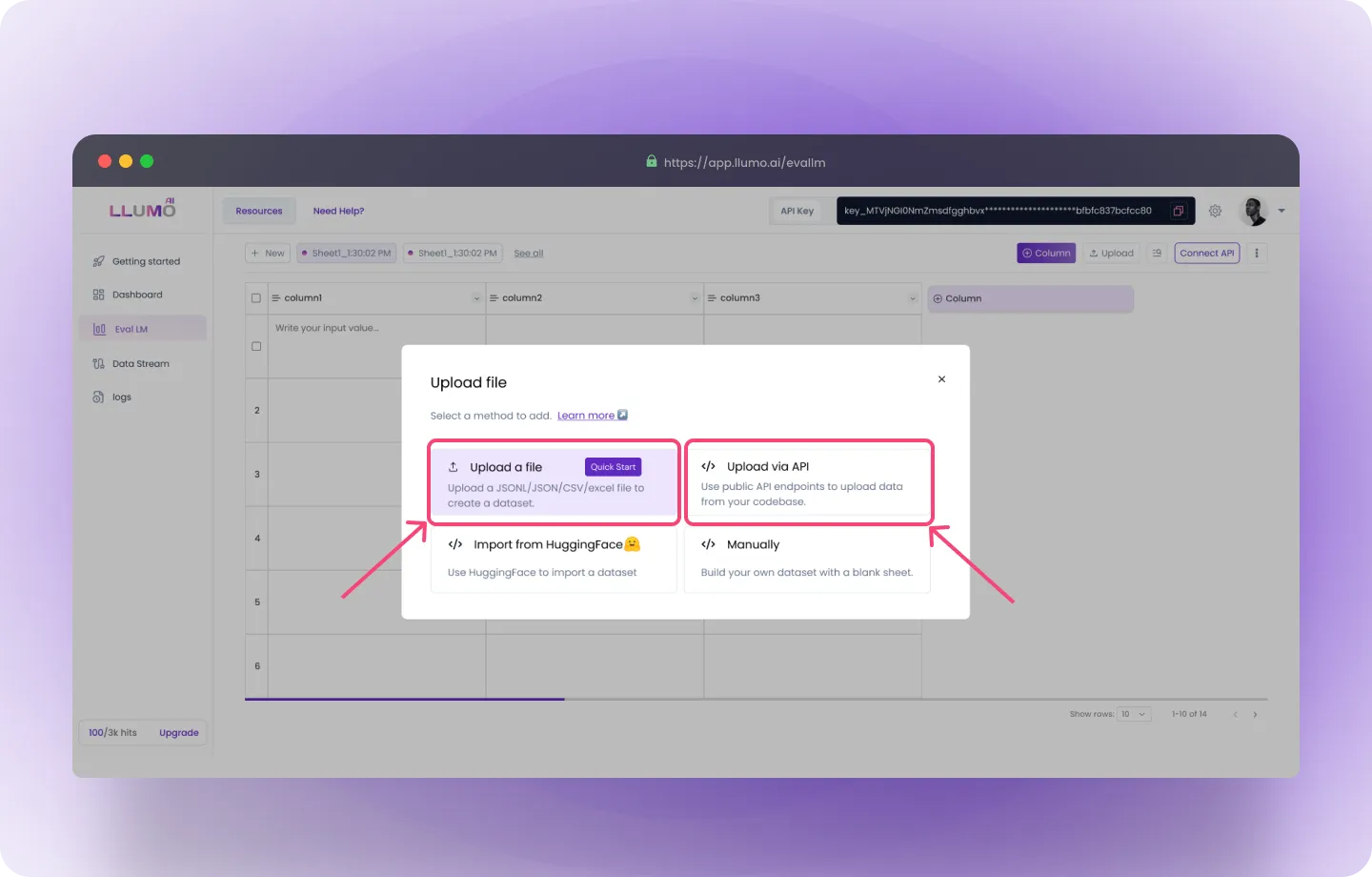 Option 1: Upload File
Option 1: Upload File
- Log into the LLUMO AI Platform and go to the “Evaluate Dataset” section.
- Click “Upload File” and select your dataset. The file can be in CSV, JSON, or Excel format.
- Review Your Data: A preview of the uploaded data will be displayed. Ensure that the file is structured correctly and the data looks accurate before proceeding.
 Option 2: Upload via API
Option 2: Upload via API
- Access the API Documentation: Visit LLUMO’s API documentation for the exact endpoint and parameters.
- Upload Your Dataset: Make an HTTP request to the API to upload your file.
- Confirm the Upload: Once the upload is complete, you’ll receive a confirmation response, and the data will be ready for evaluation.
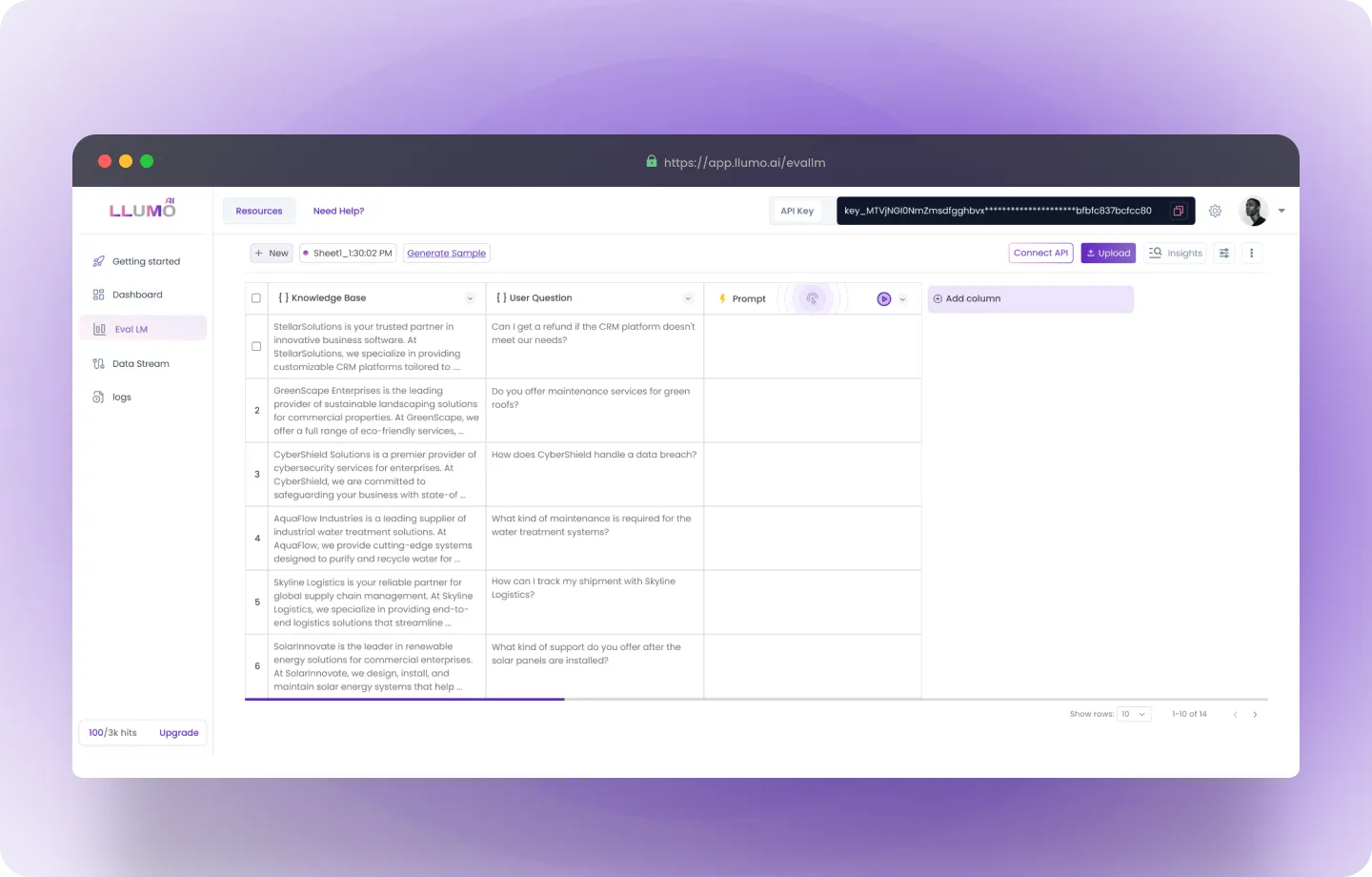
Step 2: Go to Prompt
Here, you can follow these steps:- Write Prompt: Here, enter your prompt by providing the desired query or instruction to guide the AI model in generating the results you expect.
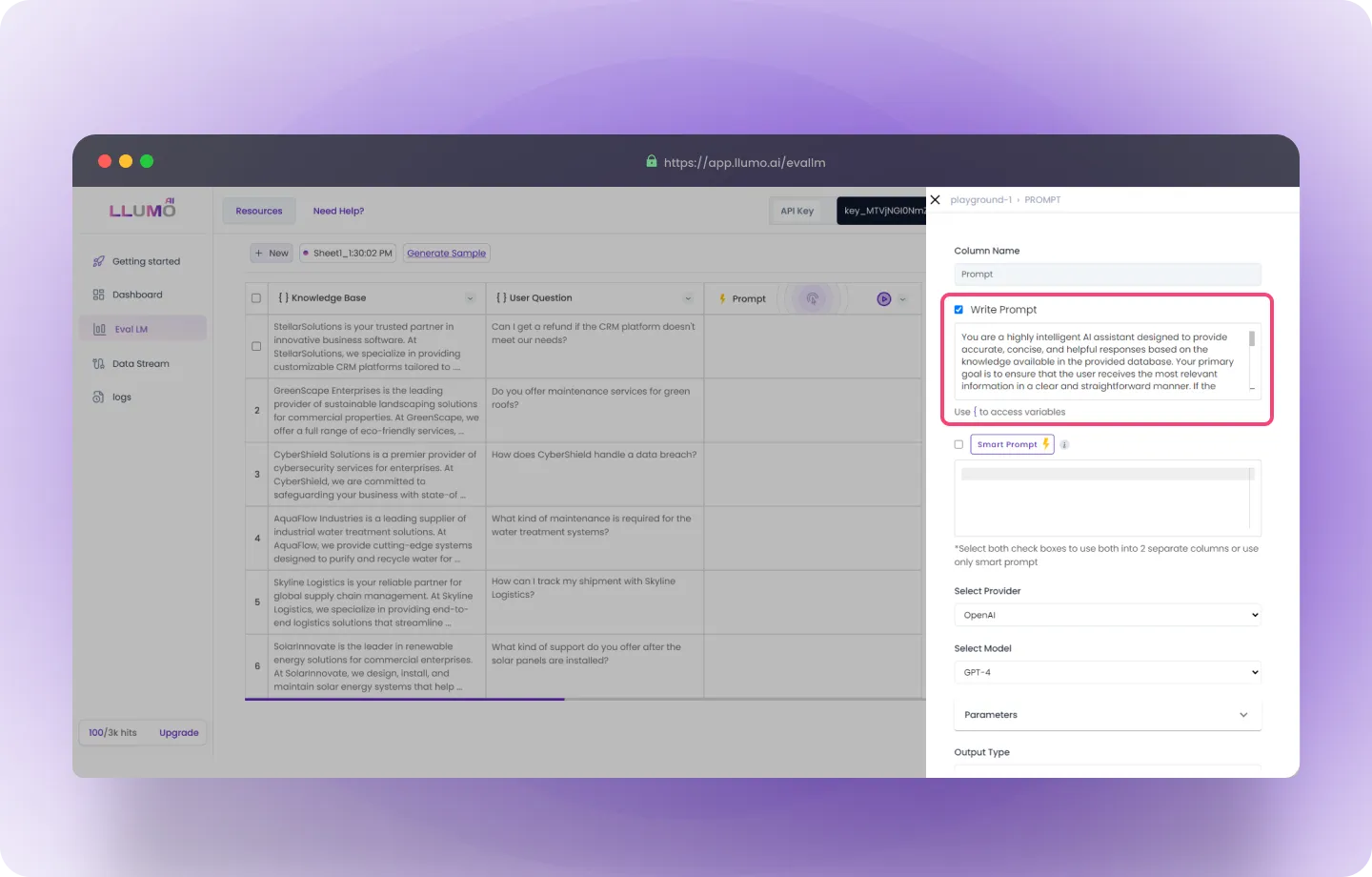
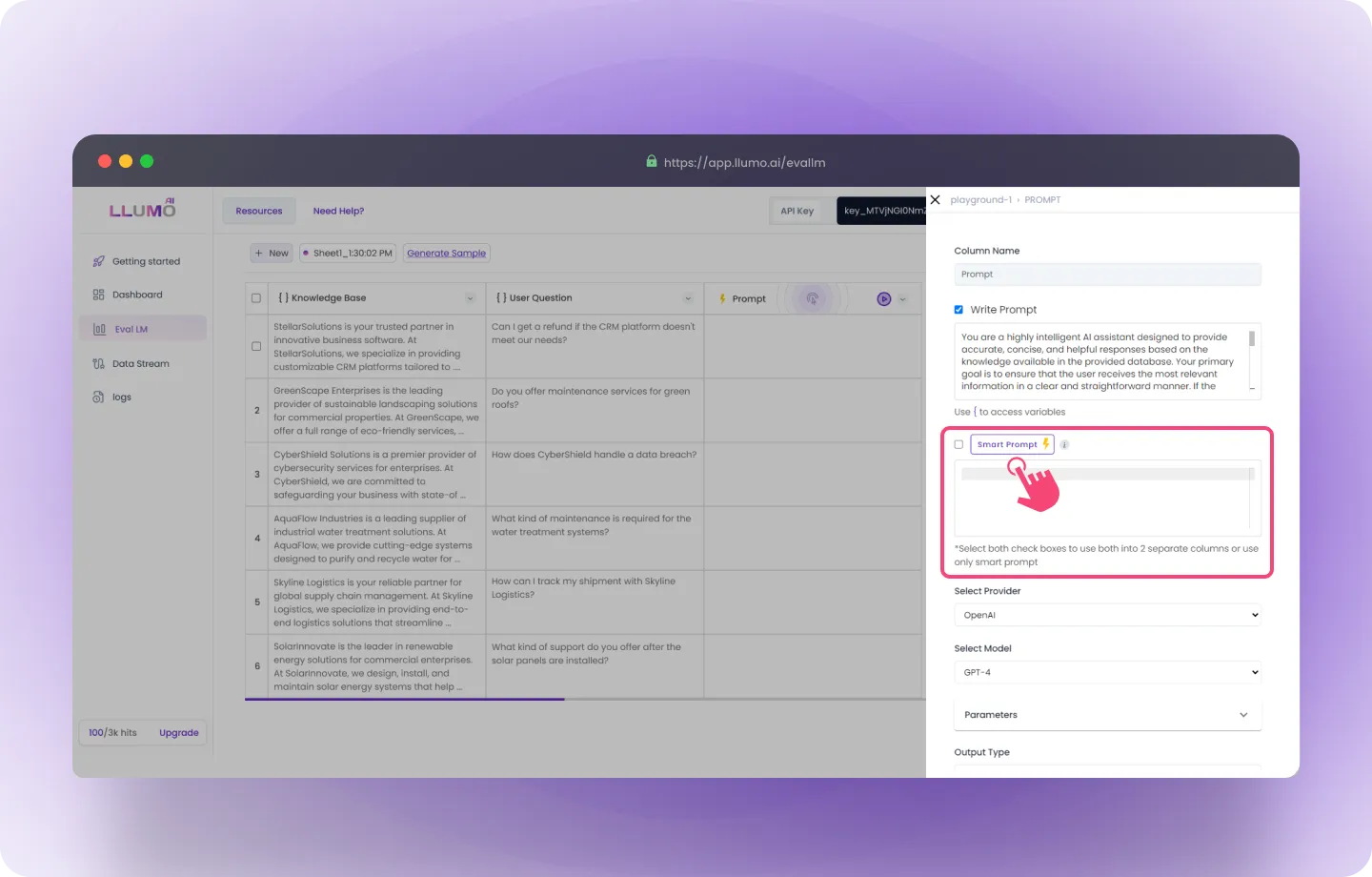
- Create a Smart Prompt: Smart Prompt refines your written prompt, making it more specific and detailed to generate more accurate and focused results.
- Select Your LLM Provider: Choose your preferred provider from the drop-down list (LLUMO supports multiple LLM providers).
- Choose the Model: Select the specific AI model you want to use for generating the results, based on your needs.
- You can choose different models to evaluate and run experiments to compare their performance on the same prompt.
- Adjust Parameters: Fine-tune the model’s parameters to match your requirements and improve output precision.
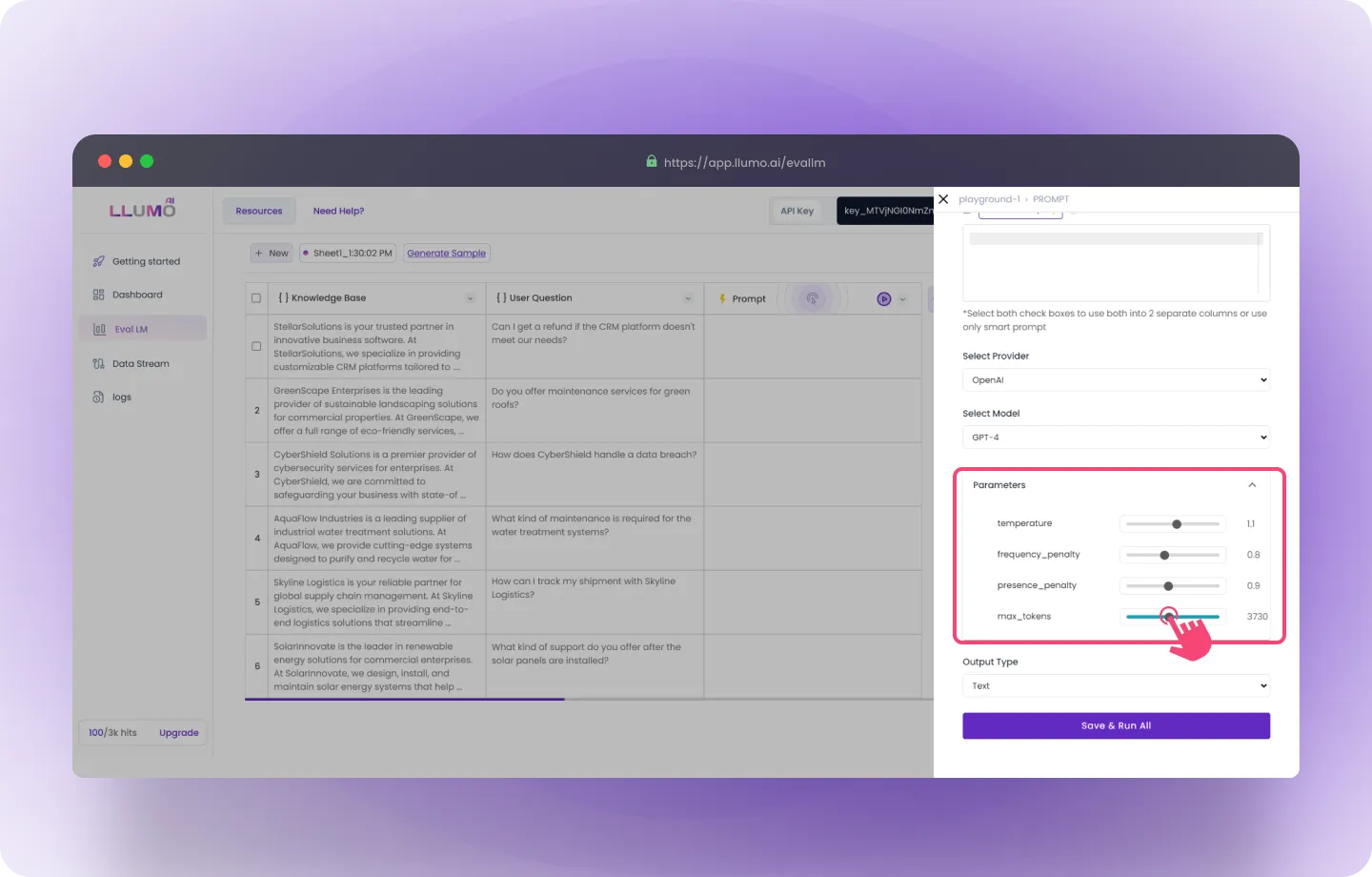
- Select Output Type: Choose the type of output you want for the generated results.
Step 3: Run the Prompts to Generate Outputs
- Once the dataset is uploaded, initiate the process to run the prompts and generate outputs.
- Allow the system to complete processing your prompts.
- Once the outputs are ready, proceed to the evaluation step.
- Here, you can observe the prompt running to generate the output. Once the output is generated, the evaluation process will begin.
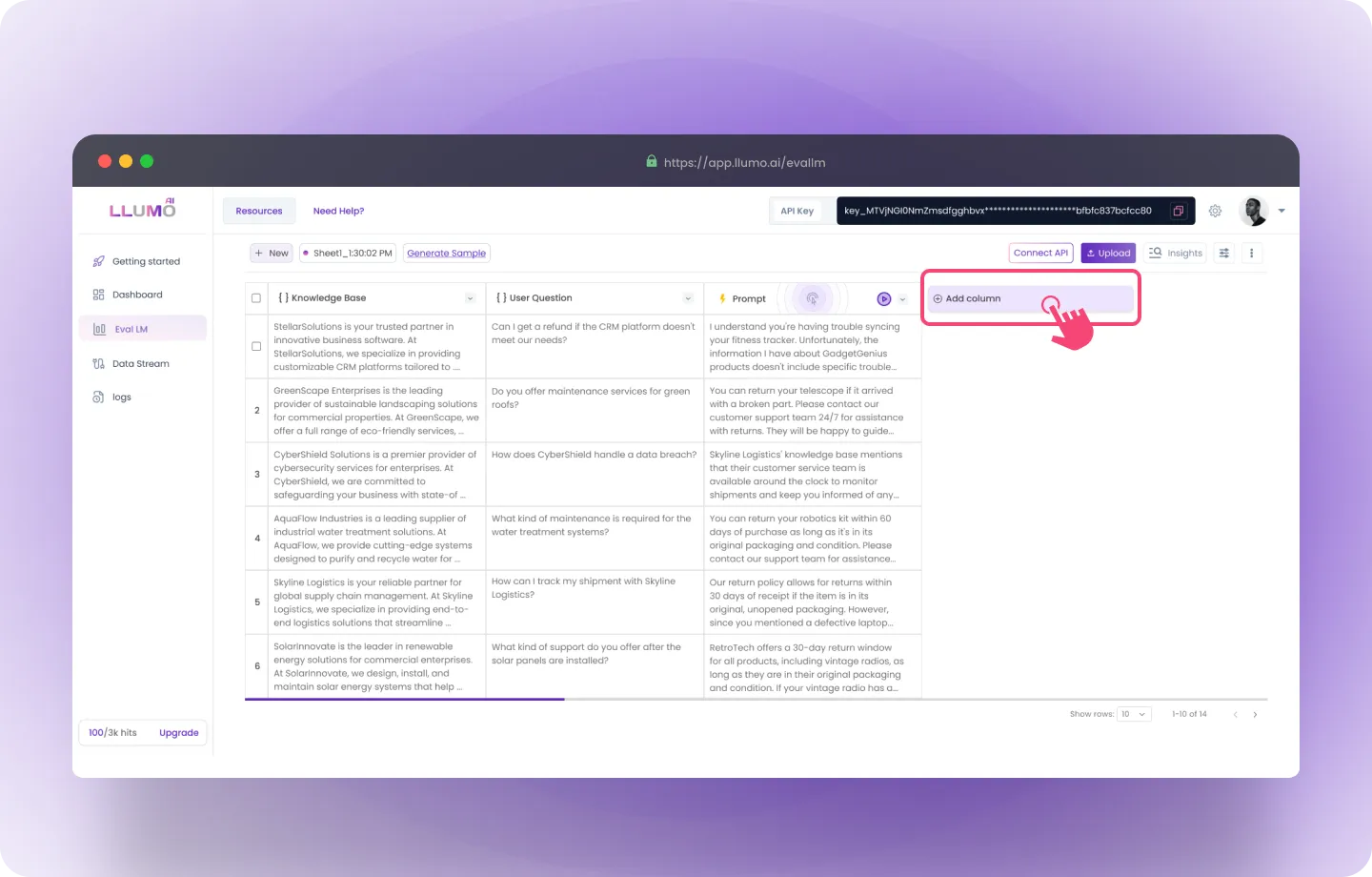
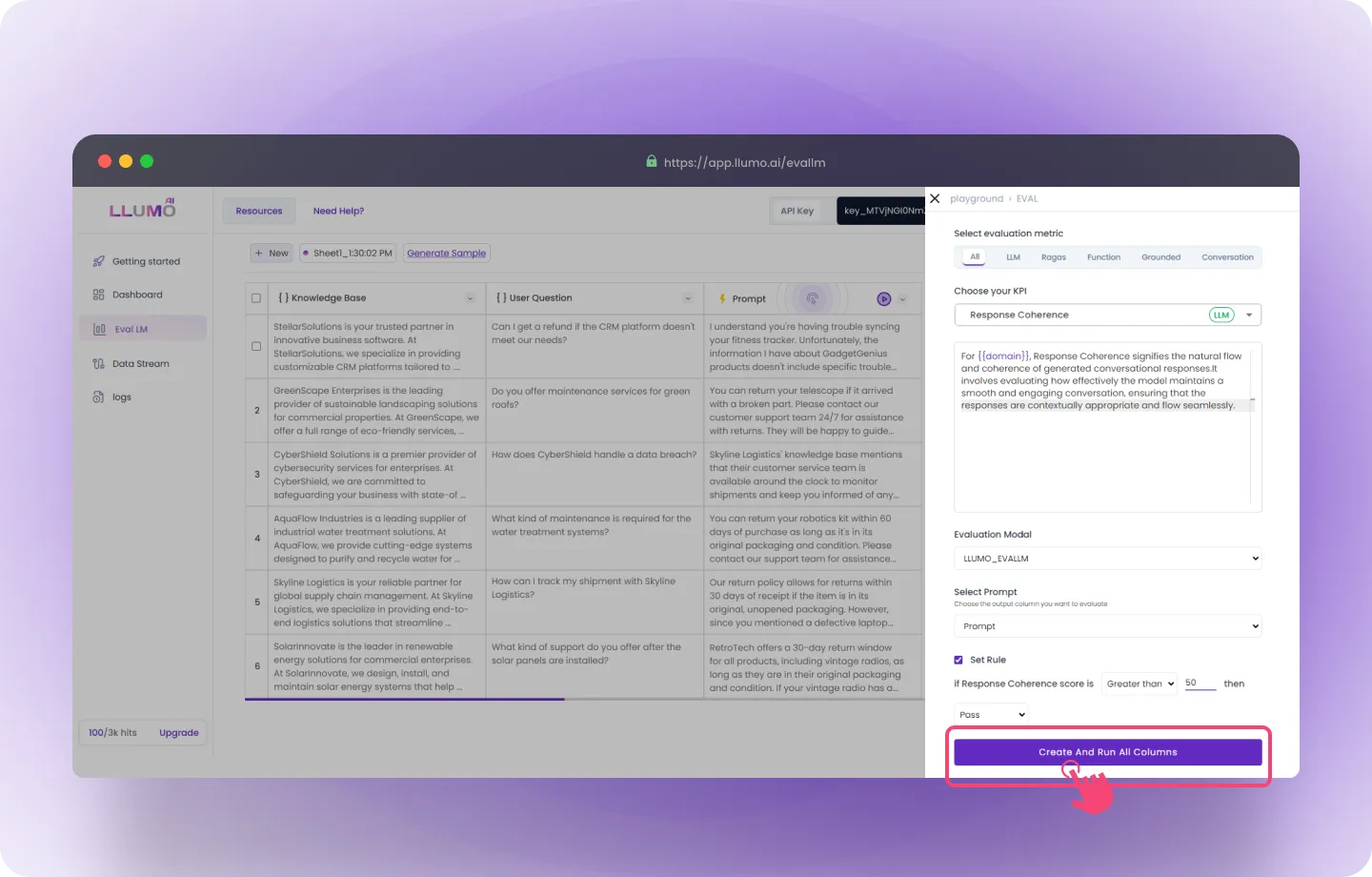
Step 3: Select Key Performance Indicators (KPIs)
- Go to the “Create Column” section and select the “Evaluation” option.
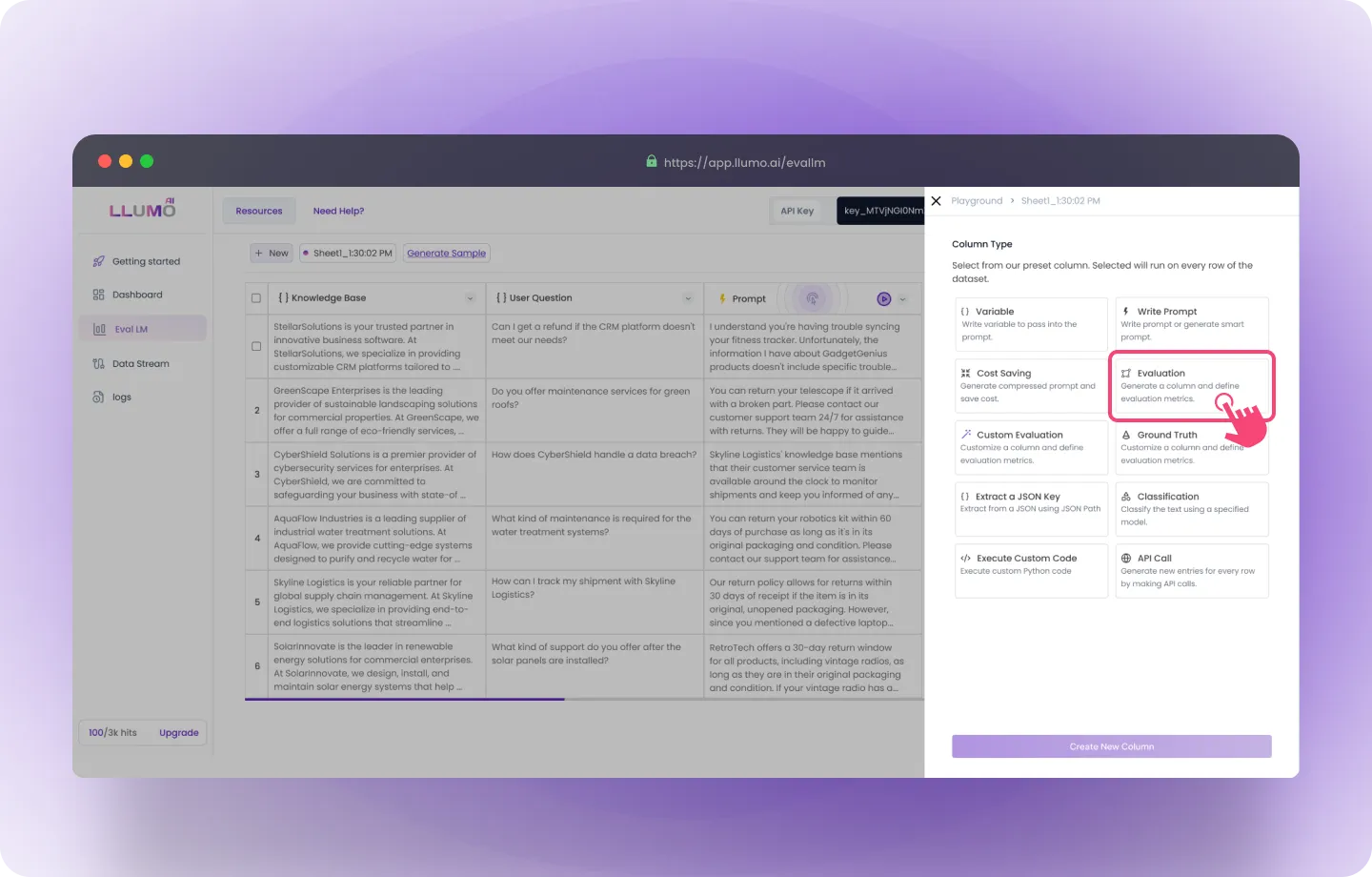
- From the dropdown menu, choose the KPIs you want to evaluate.
- Name the column where the evaluation results will be displayed.
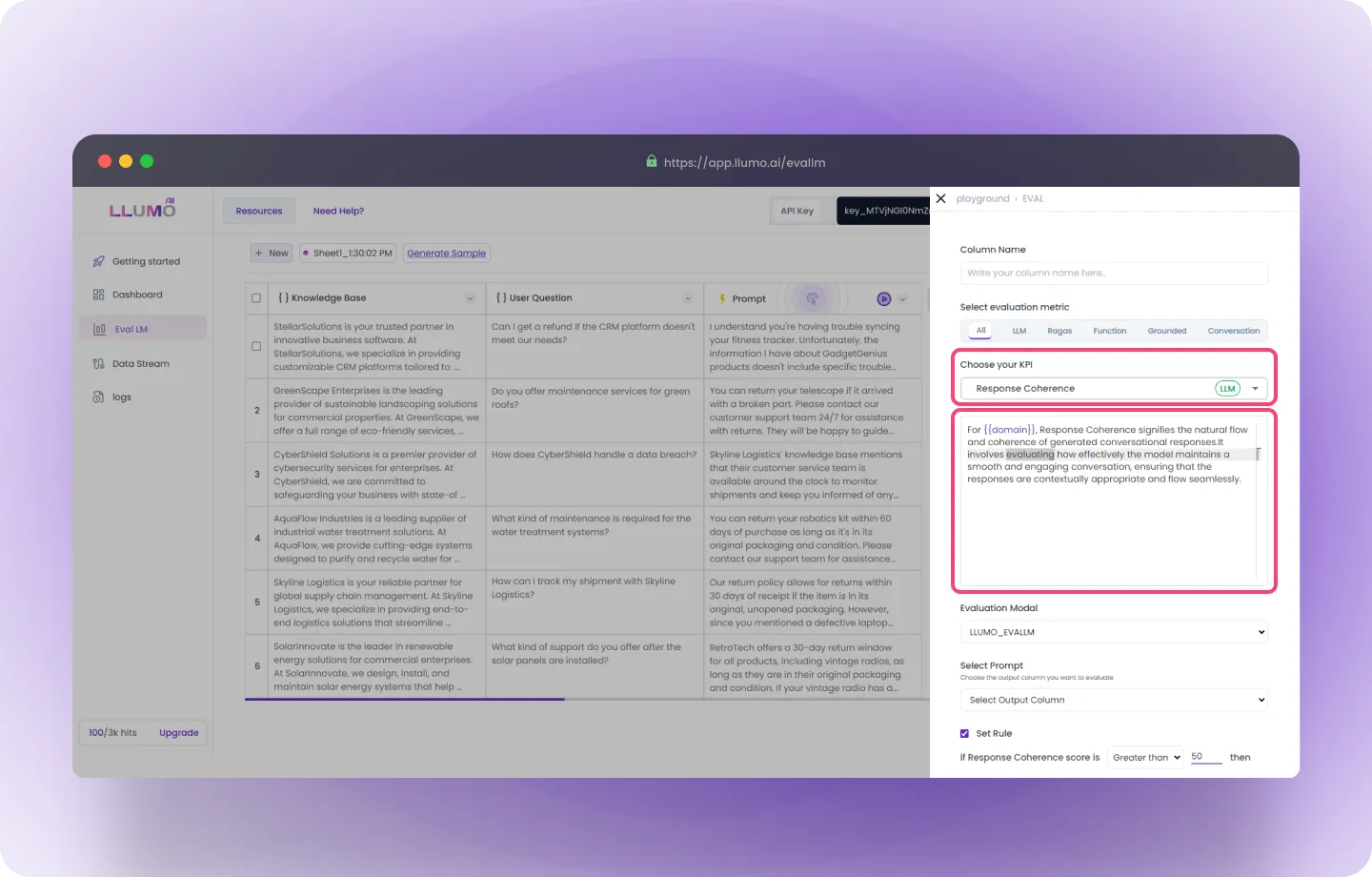
- Select the output column in your dataset that you want to evaluate. Here we are selecting our 1st metrics confidence.
- You can choose from more than 50 KPIs covering various areas of analysis, such as: Context, clarity, confidence and even many more.
Step 3: Evaluation Parameters
- Set Rule for KPIs:
- Each KPI allows you to set a specific threshold to define a “pass” or “fail.”
- Example for confidence : if the confidence score is more than 50, it passes.
Step 4: Choose Your Evaluation Model
- Select the model that best fits your evaluation needs.
Step 5: Run the Evaluation
- Start the Evaluation: After confirming your settings, click the “Create and Run All Columns” button to begin processing your evaluation.
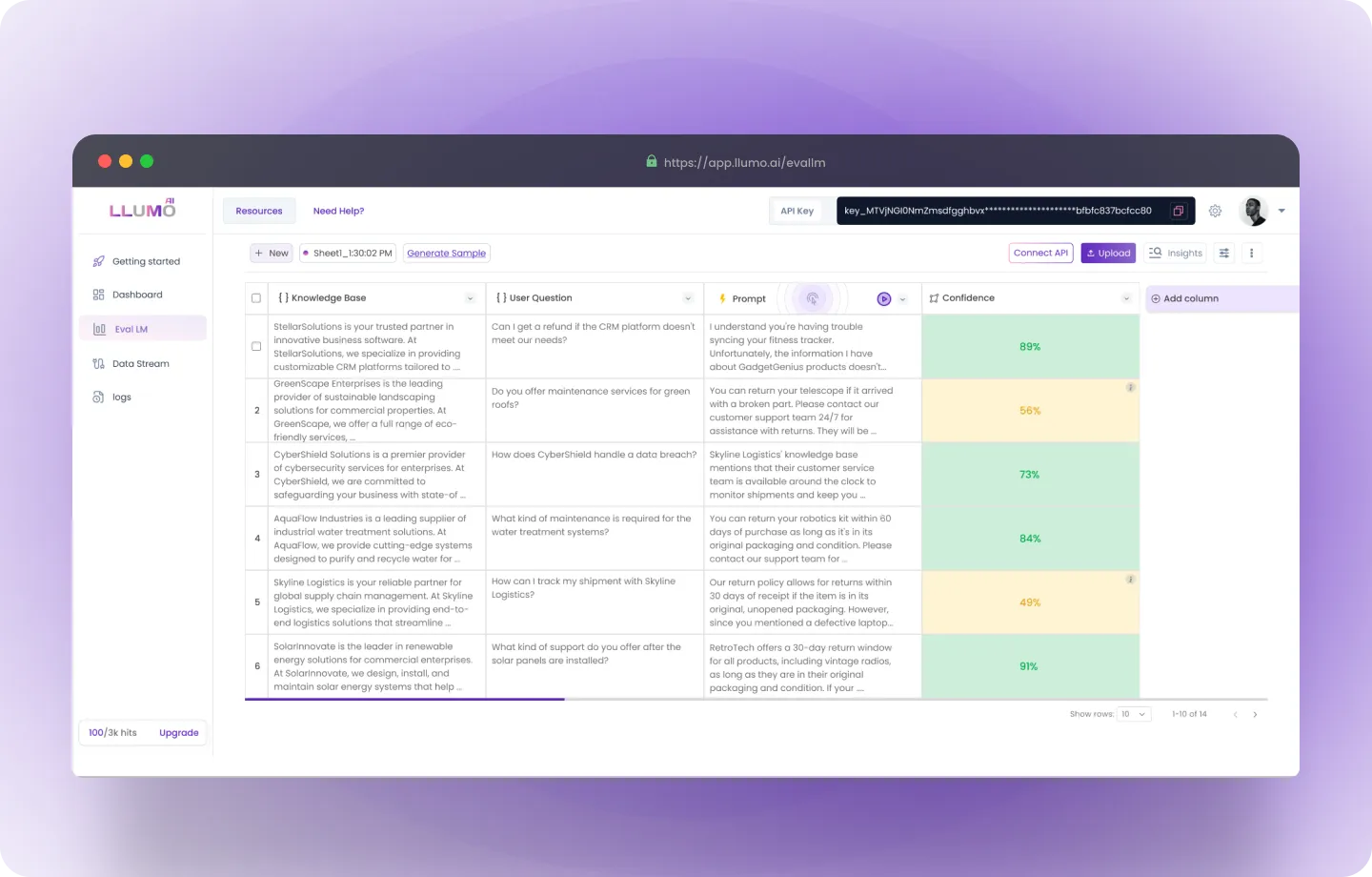
Step 6: Review Results
- Once the evaluation is complete, you’ll receive detailed results, including:
- Pass/Fail status for each KPI
- Percentage scores for each metric
- These results will help you identify areas of improvement for your AI model and refine it based on the feedback.
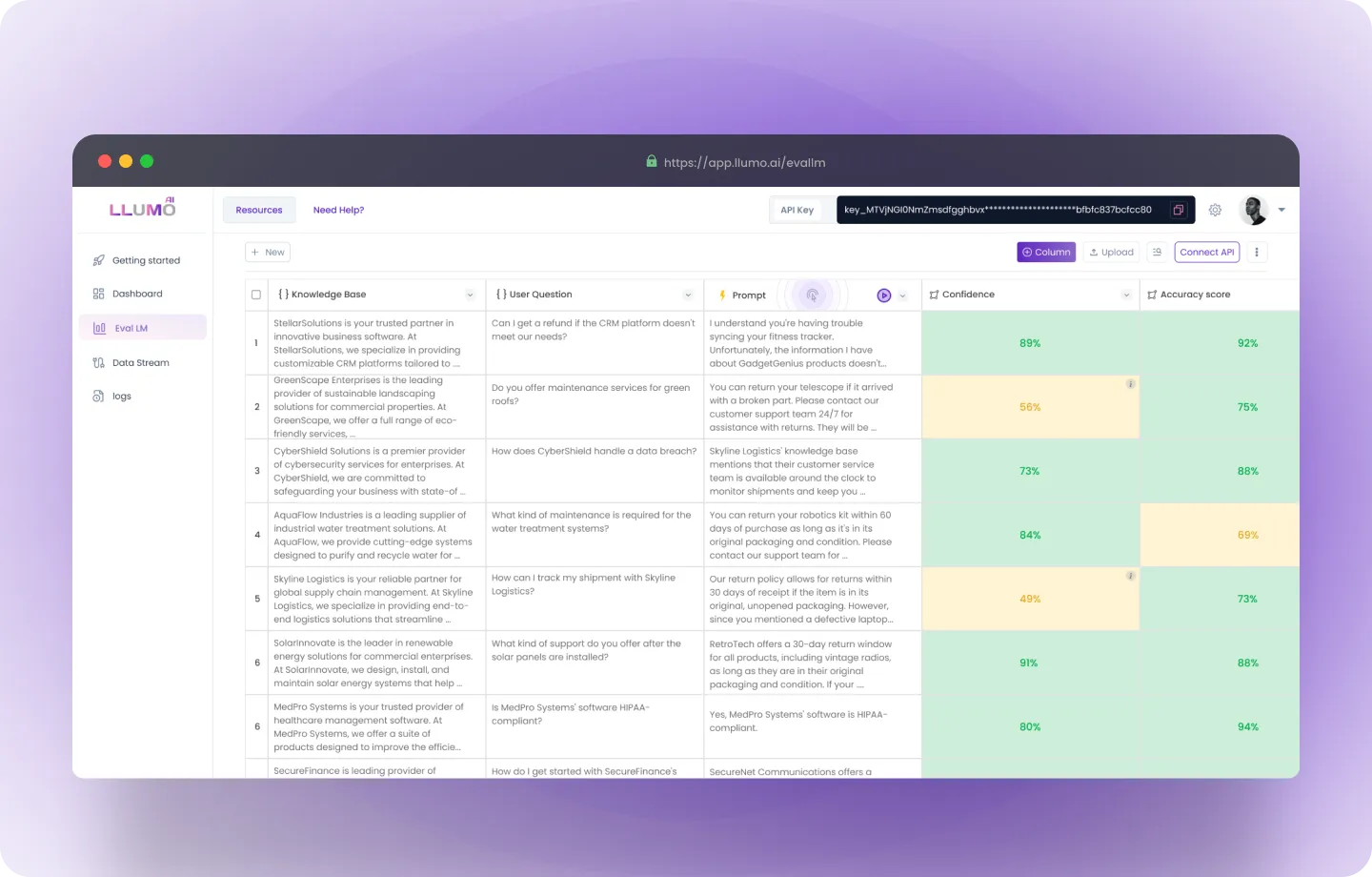
Step 7: Export Evaluation Results
- You can export the evaluation results for further analysis or reporting in CSV, Excel, or PDF format.
 LLUMO AI isn’t just about evaluating – it’s about transforming how you work with your data. The platform makes it incredibly easy to run comprehensive evaluations with multiple KPIs.
LLUMO AI isn’t just about evaluating – it’s about transforming how you work with your data. The platform makes it incredibly easy to run comprehensive evaluations with multiple KPIs.
Use Case 1: How can you perform a bulk evaluation using multiple evaluation metrics across different models at once instead of processing them individually.
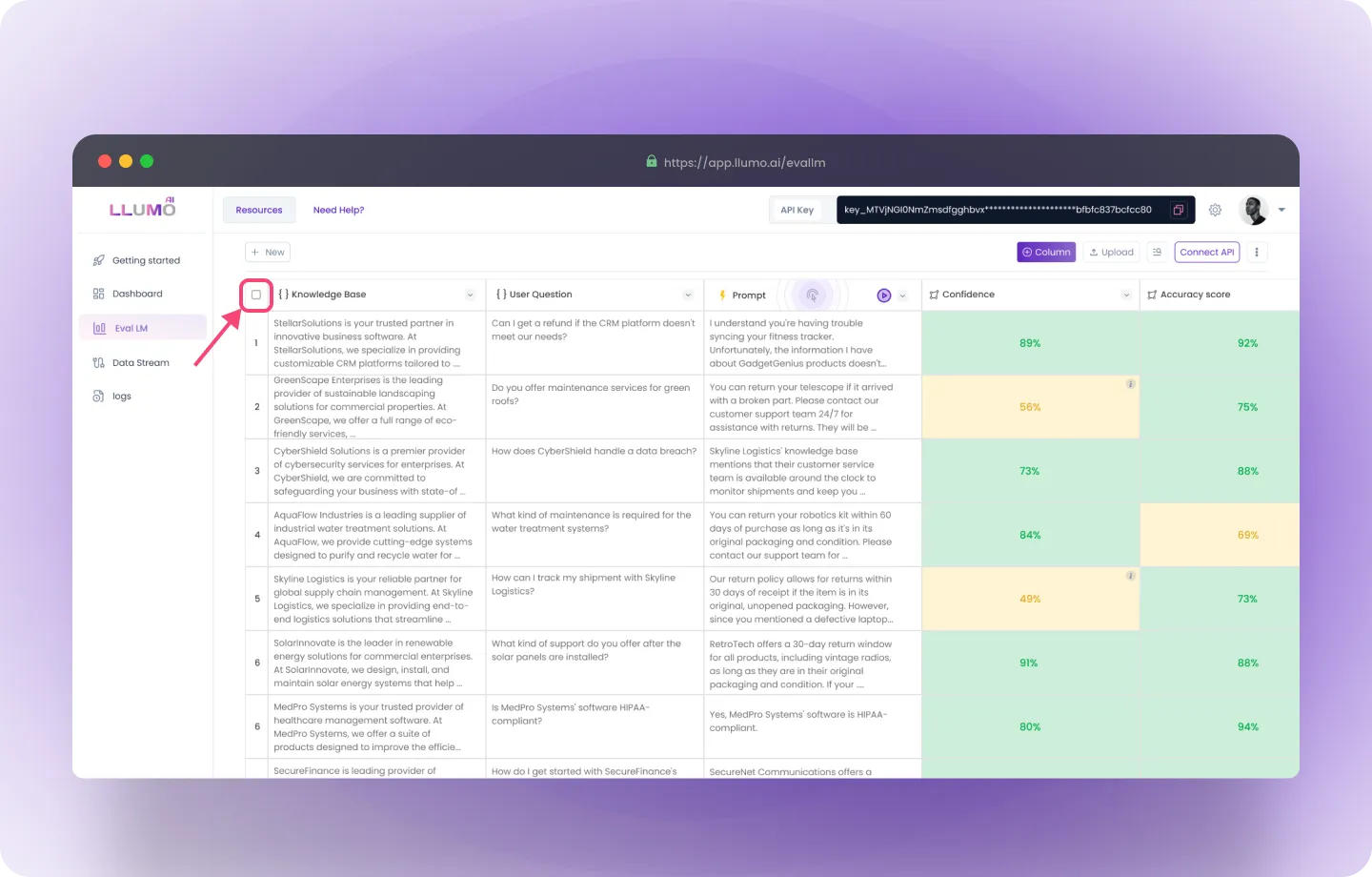
Step 1: Navigate to the box on the right side of the “Knowledge Base” section and click Select All.
- Selecting “All” ensures that the entire dataset, including all evaluation metrics and prompts, is selected. You will see an indicator confirming that 55 rows (or data entries) have been selected for evaluation.
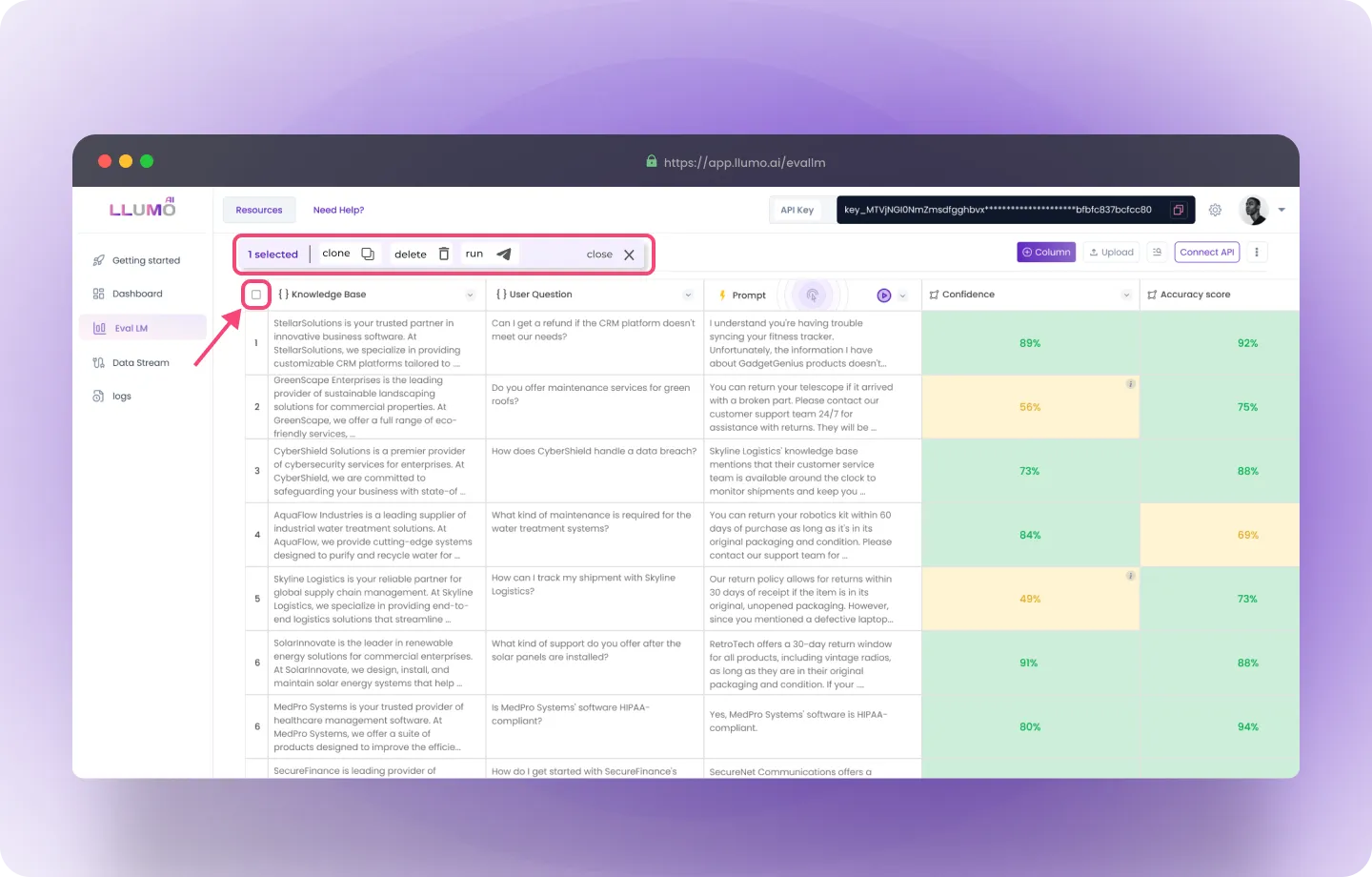
Step 2: After selecting all rows, a new menu will appear. Click on Run All in the menu.
- This action initiates the evaluation process for the entire dataset using multiple evaluation metrics across different models, all in a single click.
Step 3: Once you click Run All, the system executes the evaluation process for the selected rows.
- This includes running prompts, generating outputs, and evaluating them against your custom metrics. The evaluation results are displayed in the window, providing a detailed view of the outputs and metrics.
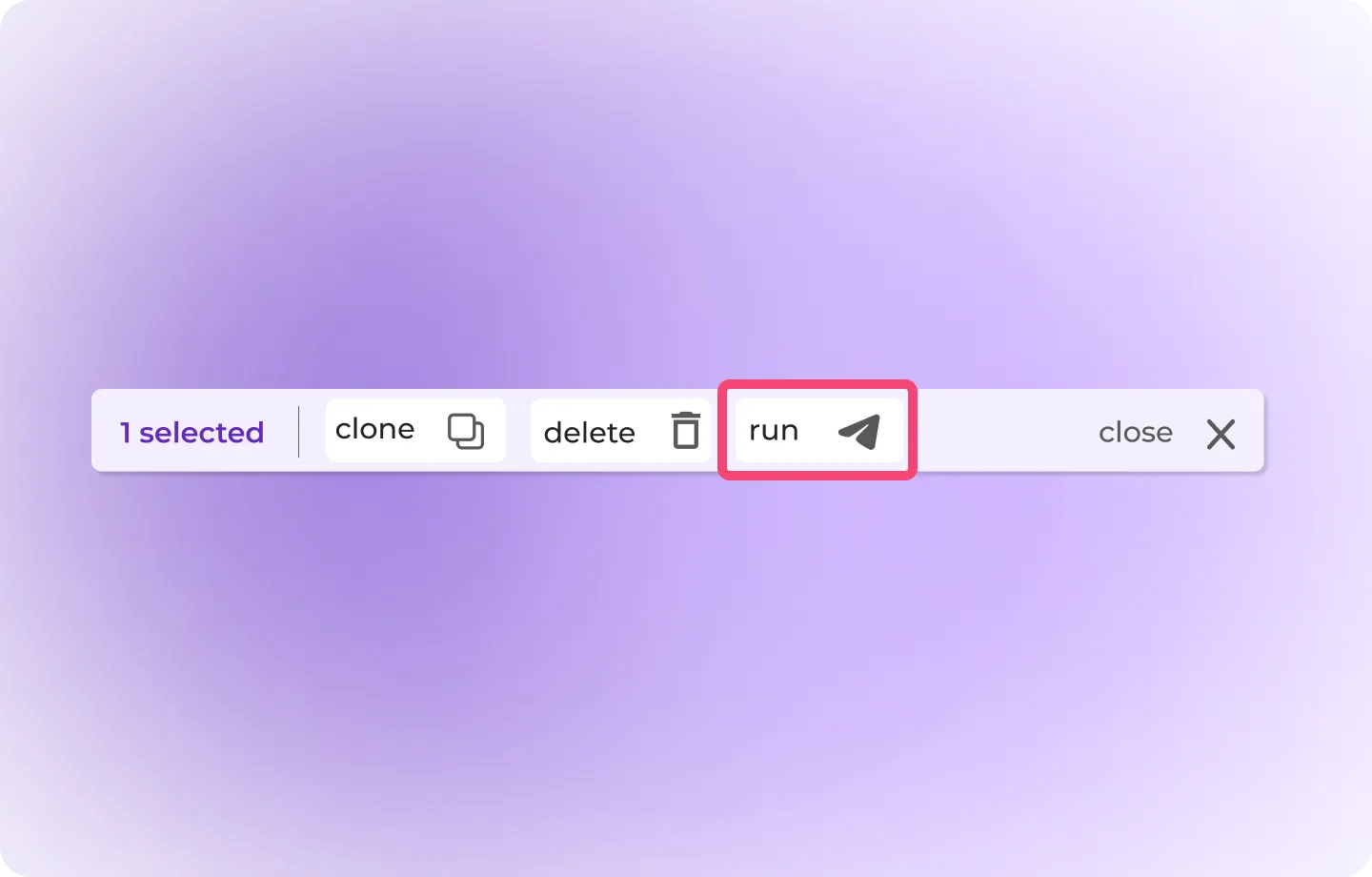
- Selected Checkbox:
- Indicates that 100 rows (or data entries) are currently selected for batch processing, such as cloning or evaluation.
- Clone Button:
- Creates a duplicate of the selected rows or data entries. Useful for experimenting with slight modifications while retaining the original data.
- Delete Button:
- Deletes the selected rows or data entries from the evaluation table. This action is typically irreversible, so users need to confirm before proceeding.
- Run Button:
- Executes the evaluation process for the selected rows. This triggers the prompt and output generation along with custom metric evaluations.
- Close Button:
- Exits the current evaluation session or clears the current selection of rows, returning users to the previous state or dashboard.
Key Terminology
Key Performance Indicators (KPIs)
- KPIs are measurable metrics used to assess the performance of your prompts and outputs.
Set Rule
- Using Set Rule, you can set minimum or maximum values that determine whether the results meet the evaluation criteria. For example, you might set a threshold of 80% accuracy for grammar quality, meaning that any output with less than 80% accuracy would fail that KPI.
Pass/Fail Criteria
- These are the conditions that must be met for an output to pass the evaluation. If an output meets or exceeds the set percentage, it passes; otherwise, it fails.
AI Models
- AI models are the underlying algorithms used to process and evaluate the outputs. LLUMO AI supports several models optimized for different evaluation tasks, such as sentiment analysis, grammar checking, or response relevance.
Frequently Asked Questions (FAQs)
What happens if my output doesn’t meet the thresholds I set?
- If an output doesn’t meet the set criteria, it will be marked as a Fail. You can review the failed outputs and adjust your model or dataset accordingly to improve performance.
Can I export my evaluation results?
- Yes, you can export the results in CSV, Excel, or PDF formats for detailed analysis or reporting purposes.
How long does the evaluation process take?
- The evaluation time depends on the size of your dataset and the complexity of the selected evaluation model. A typical evaluation of 100 prompts and outputs may take only a few minutes.
How do I handle large volumes of data efficiently during the evaluation?
- To manage large volumes of data, it’s recommended to upload files in manageable chunks or utilize the API for bulk processing.
Glossary
Knowledge Base:
- This column displays the source or baseline data (e.g., a company’s description or service information).
User Question:
- The user’s query or the input to be addressed by the AI.
Prompt:
- The prompt used to guide the AI’s response generation, likely adjusted or created by the user for optimal results.
Output Columns:
- These represent various custom evaluation metrics created for assessing the AI’s responses, such as:
- Test Confidence: Evaluates the confidence level in the AI’s response.
- Test Context: Measures the relevance of the AI’s output to the provided context.
- Test Clarity: Assesses how clear the AI-generated response is.
- Test Vocabulary: Evaluates vocabulary usage and alignment with domain-specific language or requirements.